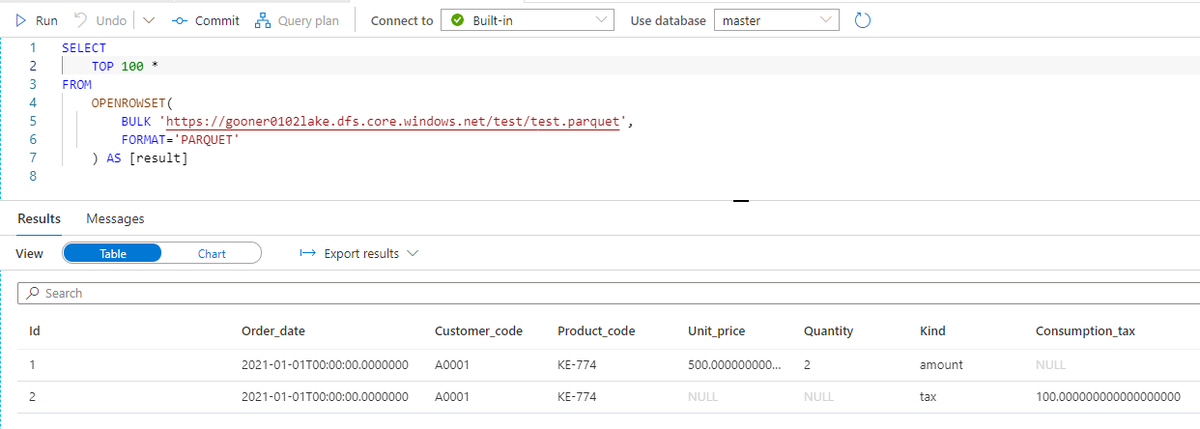
Azure Synapse Analytics を使って、売上分析プラットフォームを作ってみました。
ここでは、売上分析プラットフォームの Batch Layer を作る部分について記載します。
想定シナリオや全体アーキテクチャについては、次の記事を参照してください。
gooner.hateblo.jp
Batch Layer

Batch Layer は、DataLake から DWH を作る責務を持ちます。
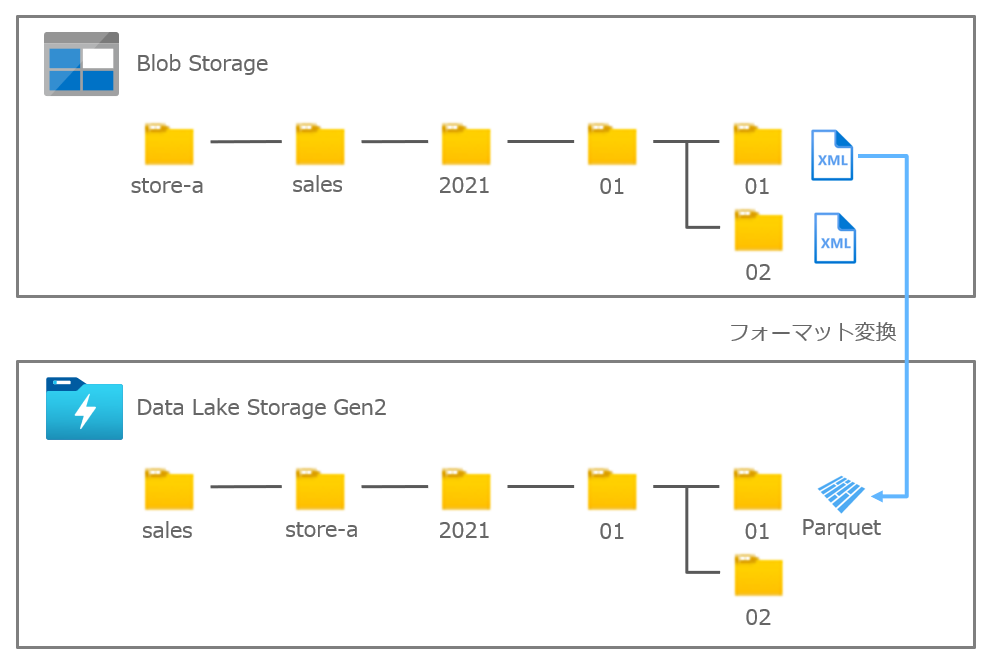
Mapping Data Flow を使って、Azure Data Lake Storage Gen2(ADLS)の Parquet から Dedicated SQL Pool に売上データを取り込むパイプラインを作成します。
売上データを取り込む過程で、SQL Database の顧客マスターと突き合わせて、各店舗のローカルコードを標準コードに変換します。
Datasets を作成する
利用するリソースごとに、3つの Datasets を作成します。
Datasets for ADLS
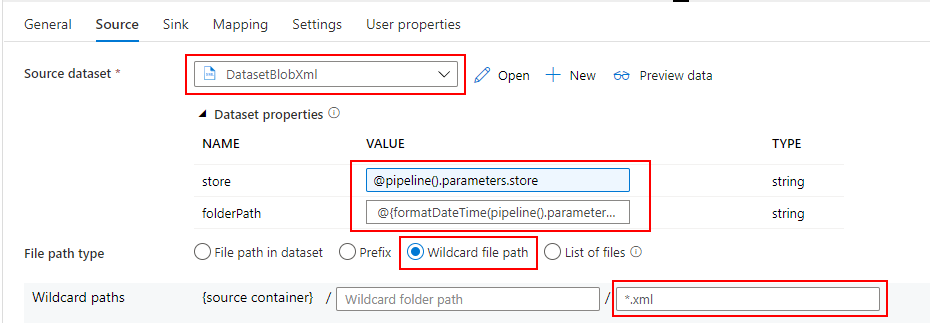
ADLS に配置されている Parquet を参照するための Datasets を作成します。
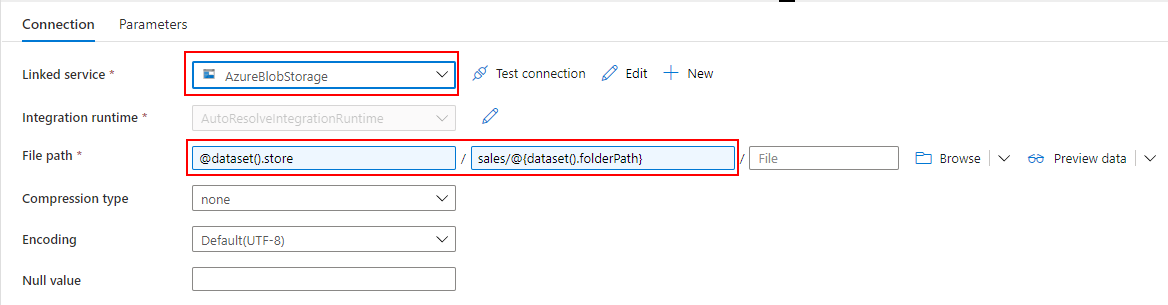
Linked service には、Synapse Analytics の Default Storage(ADLS)を指定し、file path でコンテナ名の sales を入力します。
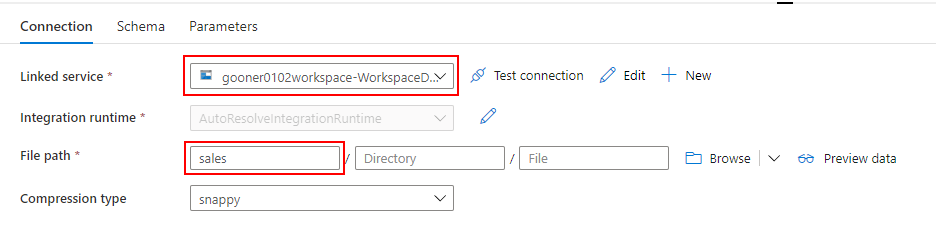
sales コンテナの直下に店舗毎に日付別のフォルダ(e.g. sales/store-a/2021/01/01)を作成して Parquet ファイルを配置しています。
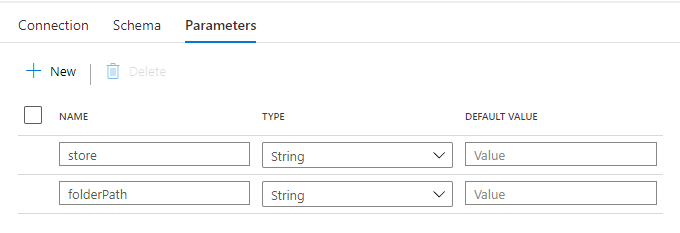
Datasets に引数を作りたかったのですが、Mapping Data Flow から値を引き渡すことができませんでした。そのため、ここではコンテナ名のみを入力して、Mapping Data Flow 側で file path を上書きするように構成します。
Datasets for SQL Database
SQL Database の顧客マスターを参照するための Datasets を作成します。
Linked service には SQL Database を指定し、Table で CustomerView を選択します。

Datasets for Dedicated SQL Pool
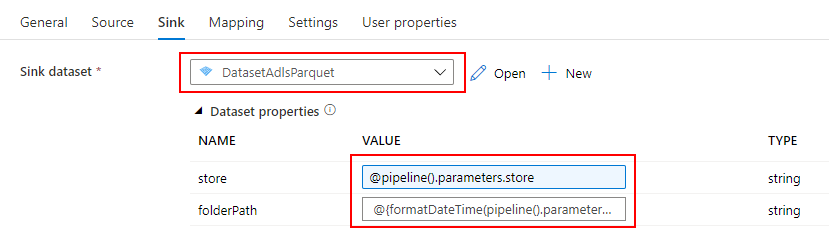
Dedicated SQL Pool に売上データを取り込むための Datasets を作成します。
Linked service には Dedicated SQL Pool を指定し、DbName の SQLDW1 と Table の Sales を入力します。
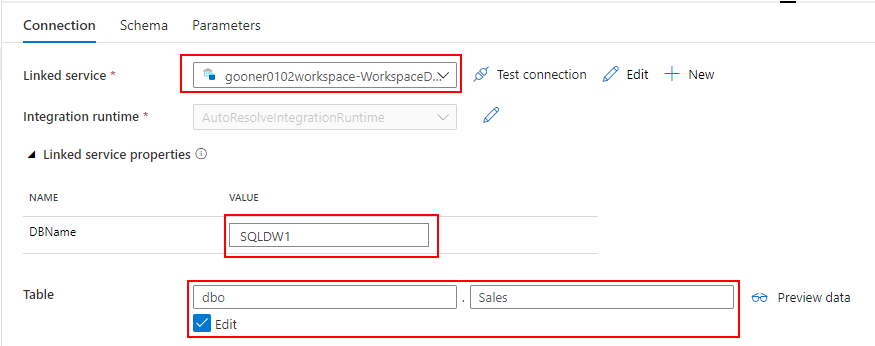
Linked service を指定する際の注意点として、"Azure Synapse Dedicated SQL Pool" ではなく、"Azure Synapse Analytics" を選択してください。Mapping Data Flow から Datasets を指定する際に、なぜか "Azure Synapse Dedicated SQL Pool" を選択できないためです。
Mapping Data Flow を作成する
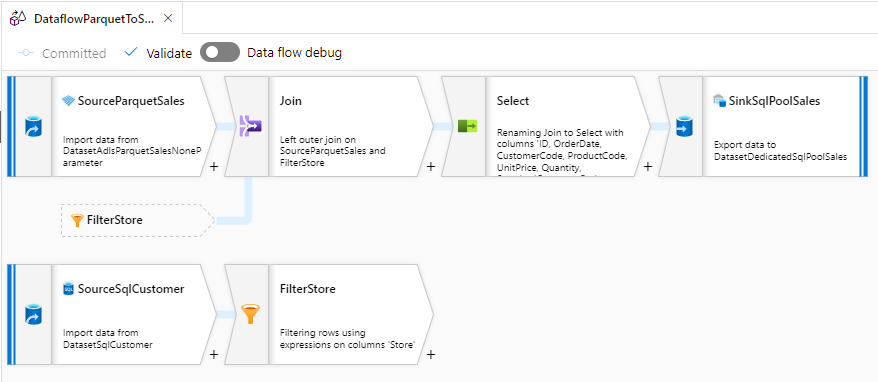
ADLS の Parquet から Dedicated SQL Pool にデータを取り込む Mapping Data Flow の完成イメージです。
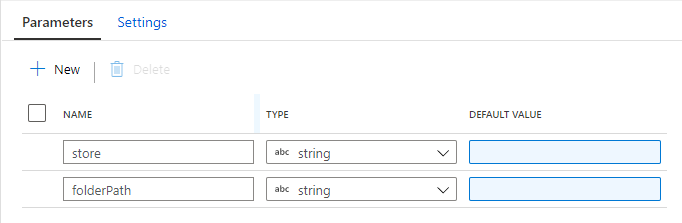
Parameter
Mapping Data Flow の Parameter を設定します。
store は、パイプラインを全店舗で共通化して、Trigger を店舗毎に作る想定のため、店舗を指定します。
folderPath は、日次でフォルダ分けされた Parquet ファイルの場所を指定します。
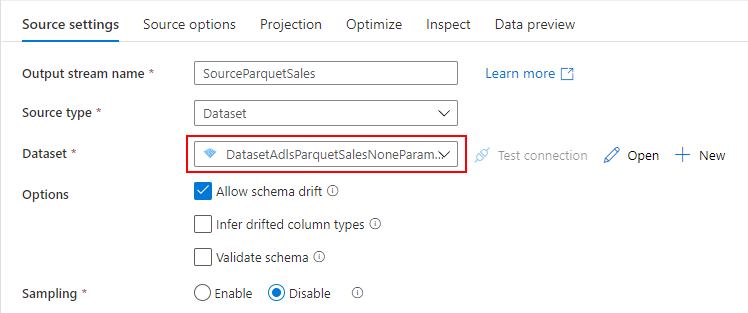
Source(ADLS 用)
ADLS に配置されている Parquet を参照したいので、先ほど作成した ADLS 用の Datasets を指定します。
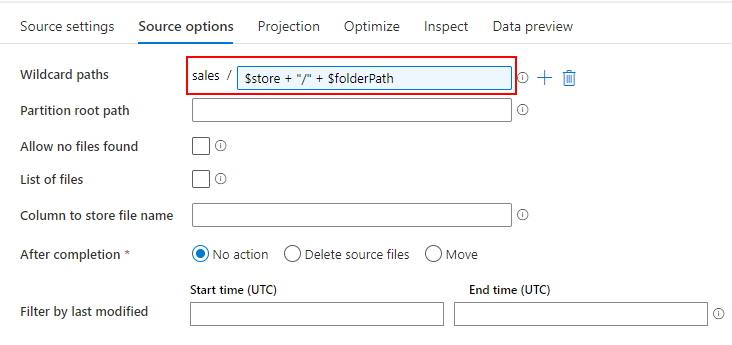
Wildcard paths には、$store + "/" + $folderPath を入力します。これにより、Parameter で受け取った値を使って動的に読み取りパスを決定することができます。
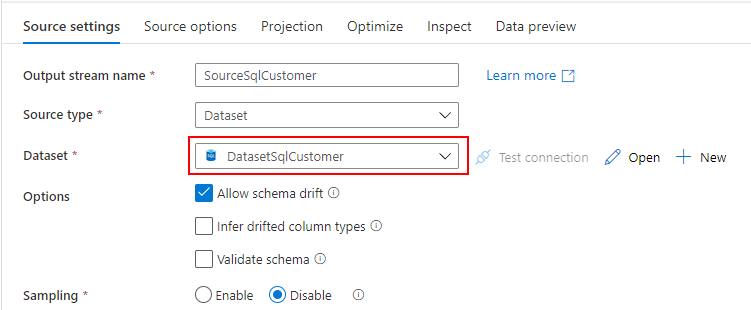
Source(SQL Database 用)
SQL Database に配置されている顧客マスターを参照したいので、先ほど作成した SQL Database 用の Datasets を指定します。
Filter
SQL Database の CustomerView は、全店舗の顧客マスターが返されるため、Parameter で受け取った store で Filter します。
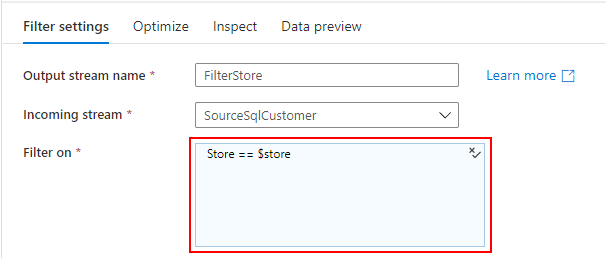
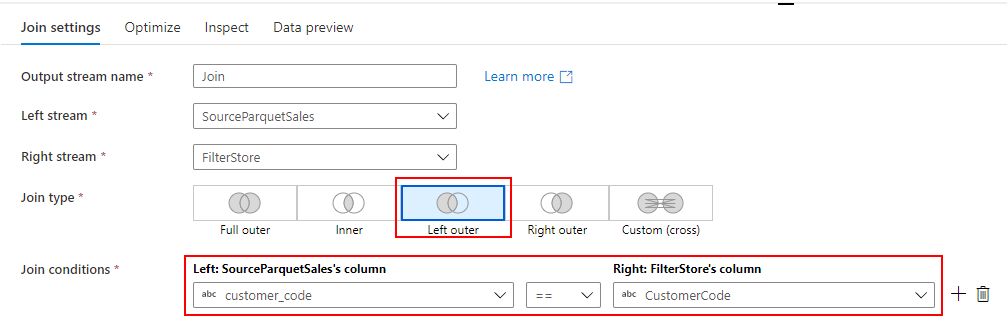
Join
2つの Source(Parquet の売上データと SQL Database の顧客マスター)を Customer Code をキーに Left Outer Join します。
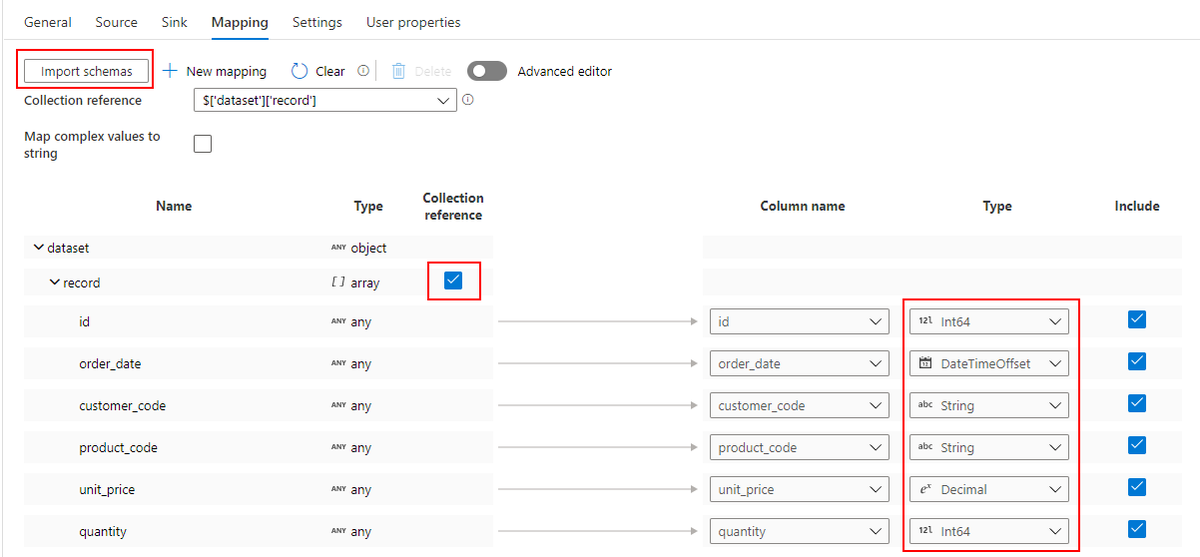
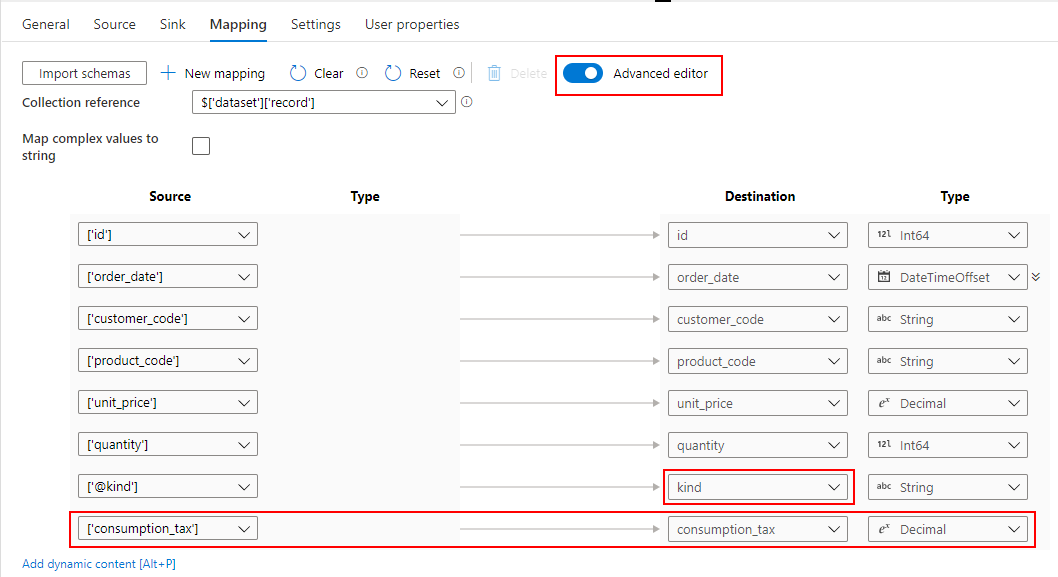
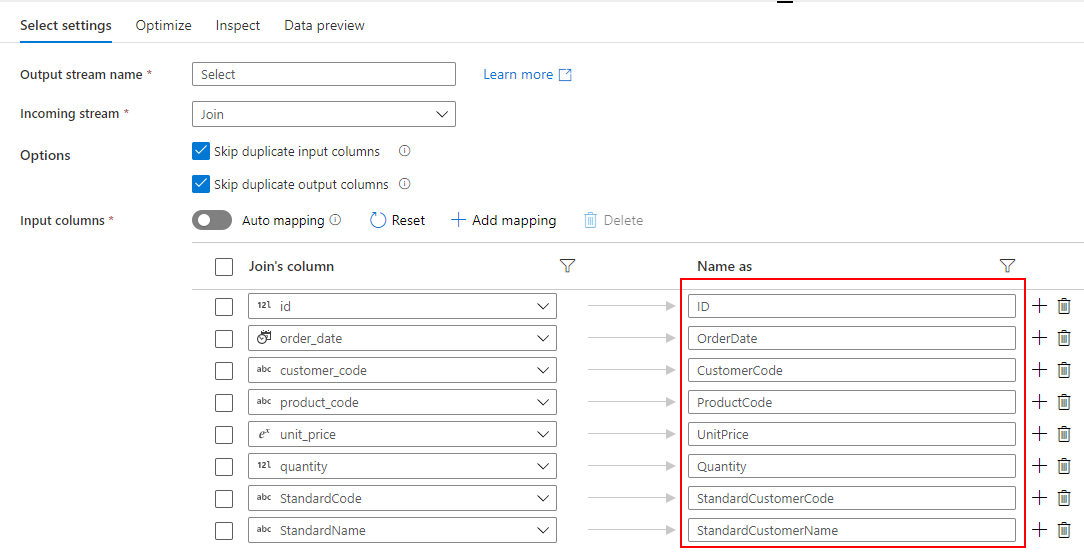
Select
2つの Source を Join した結果のうち、必要ない列を削除して、Dedicated SQL Pool に取り込む列名を設定します。
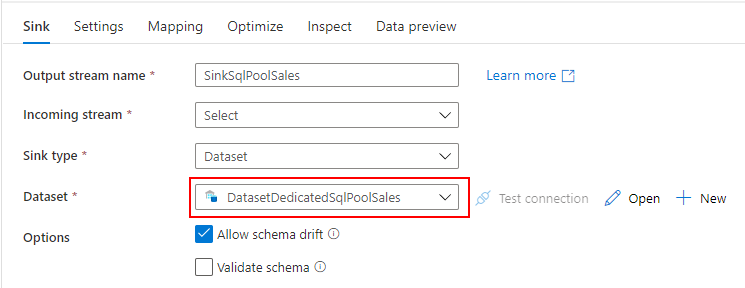
Sink
Dedicated SQL Pool に売上データを取り込み取りたいので、先ほど作成した Dedicated SQL Pool 用の Datasets を指定します。
以上で、Mapping Data Flow の作成が完了しました。
Pipeline を作成する
Mapping Data Flow を実行するパイプラインを作成します。
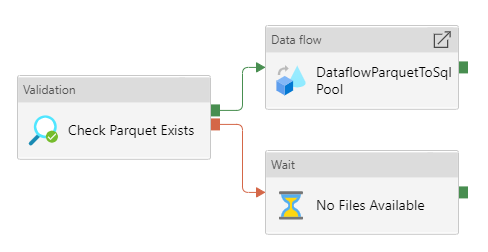
Parameter
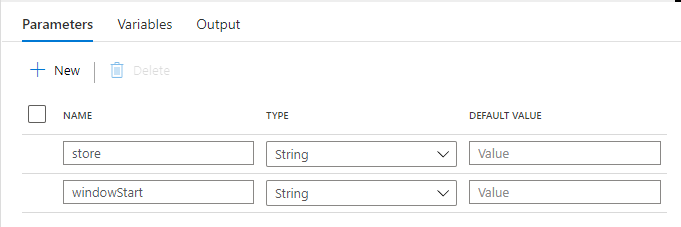
Mapping Data Flow と同様に、パイプライン の Parameter を設定します。

Data Flow
先ほど作成した Mapping Data Flow を指定します。Staging の領域が必要となるので、Synapse Analytics の Default Storage(ADLS)に任意のコンテナを指定します。
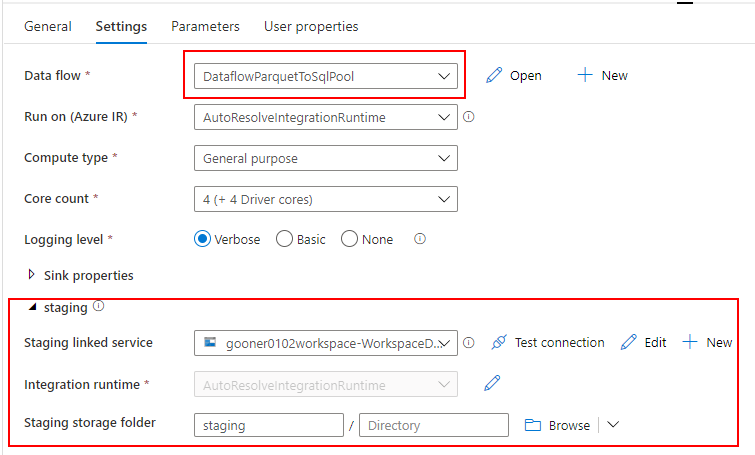
パイプラインの Parameter を Mapping Data Flow の Parameter に引き渡します。

"store": @pipeline().parameters.store, "folderPath": @{formatDateTime(pipeline().parameters.windowStart,'yyyy')}/@{formatDateTime(pipeline().parameters.windowStart,'MM')}/@{formatDateTime(pipeline().parameters.windowStart,'dd')}
Validation
Validation Activity を使って、ADLS の Parquet ファイルの存在をチェックします。
フォルダだけでなく、ファイルの存在もチェックしたいので、Child Items には TRUE を指定します。それ以外の Datasets と Parameter は、同様に設定します。

以上で、パイプラインの作成が完了しました。
パイプラインを動作確認する
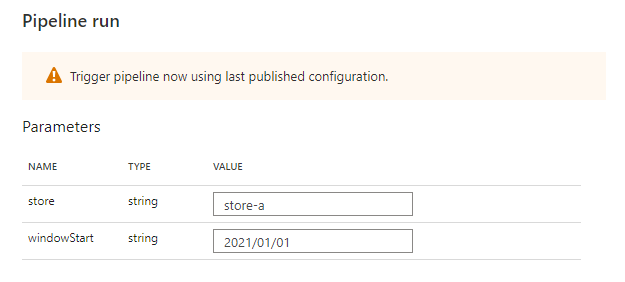
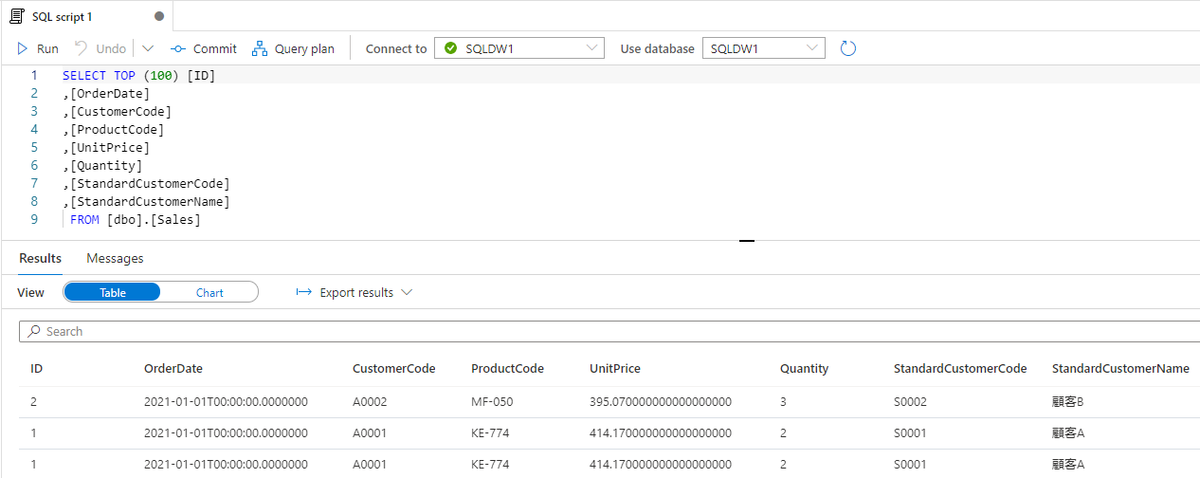
パイプラインの Trigger now から、Parameter を指定して実行してみます。

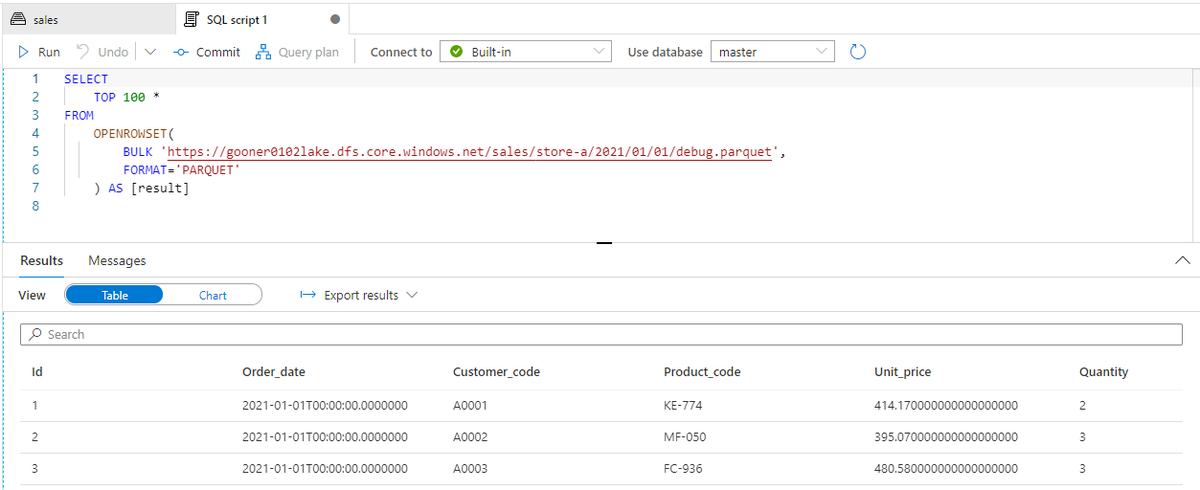
パイプラインが成功すると、標準顧客コードをマッピングした売上データが Dedicated SQL Pool の Sales テーブルに取り込まれたことを確認できます。
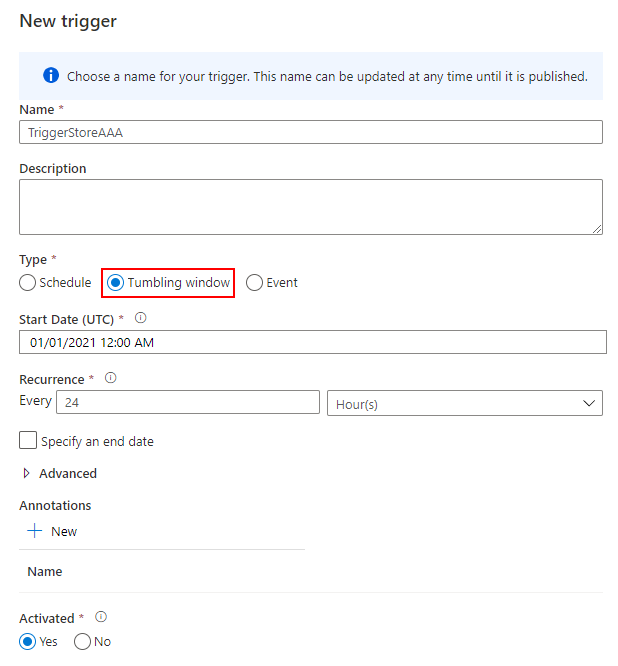
Trigger を作成する
最後に、日次実行するトリガーを作成して完了です。Tumbling window を 24 時間の間隔で実行します。
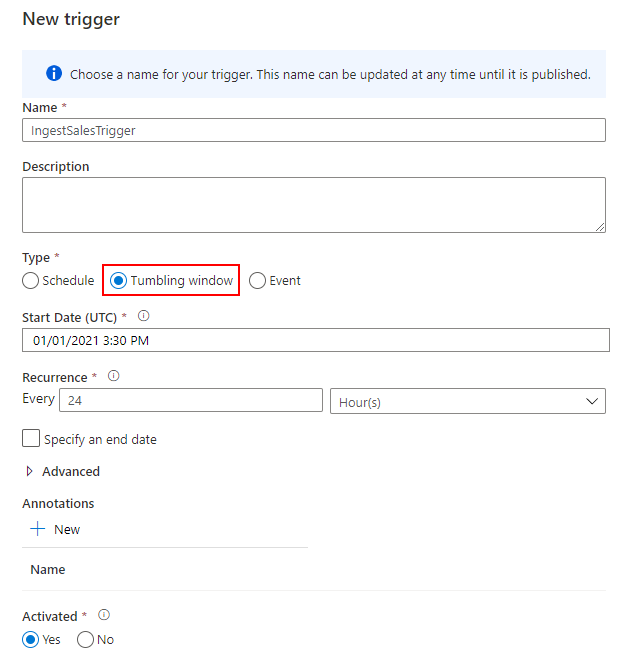
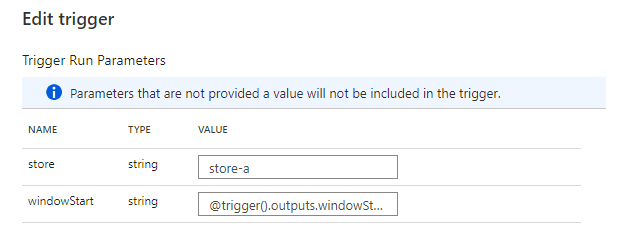
トリガーの実行開始時刻を windowStart でパイプラインに引き渡します。トリガーを店舗ごとに作る想定なので、store を決め打ちしています。
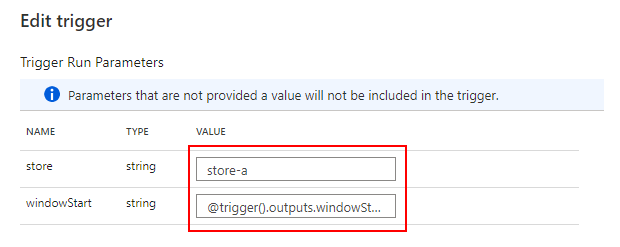
{ "store": store-a, "windowStart": @trigger().outputs.windowStartTime }
Schedule でも代用できますが、リトライポリシーを設定できる Tumbling window を選択しました。
docs.microsoft.com
まとめ
Azure Synapse Analytics を使って、売上分析プラットフォームの Batch Layer を作ってみました。
Mapping Data Flow のアクティビティを使いこなせるようになって、もう少し複雑なクレンジングも作れるようになりたいところです。
今回のソースコードは、こちらで公開しています。
github.com