Azure Synapse Analytics を使って、売上分析プラットフォームを作ってみました。
ここでは、売上分析プラットフォームの Ingest Layer を作る部分について記載します。
想定シナリオや全体アーキテクチャについては、次の記事を参照してください。
gooner.hateblo.jp
Ingest Layer

Ingest Layer は、収集したデータから DataLake を作る責務を持ちます。
Copy Data を使って、Blob Storage の XML を Parquet に変換して Azure Data Lake Storage Gen2(ADLS)にコピーするパイプラインを作成します。
techcommunity.microsoft.com
この記事によれば、Mapping Data Flow でも XML に対応しているようですが、うまく動かなかったので、今回は Copy Data を使うことにしました。
ディレクトリ構成
Blob Storage と ADLS のディレクトリは、日次でパイプラインを実行したいので日付で分ける構成とします。
この構成であれば、何らかの障害発生時に再試行しやすいですし、ファイル数が増えてもパフォーマンスに影響を与えにくいはずです。
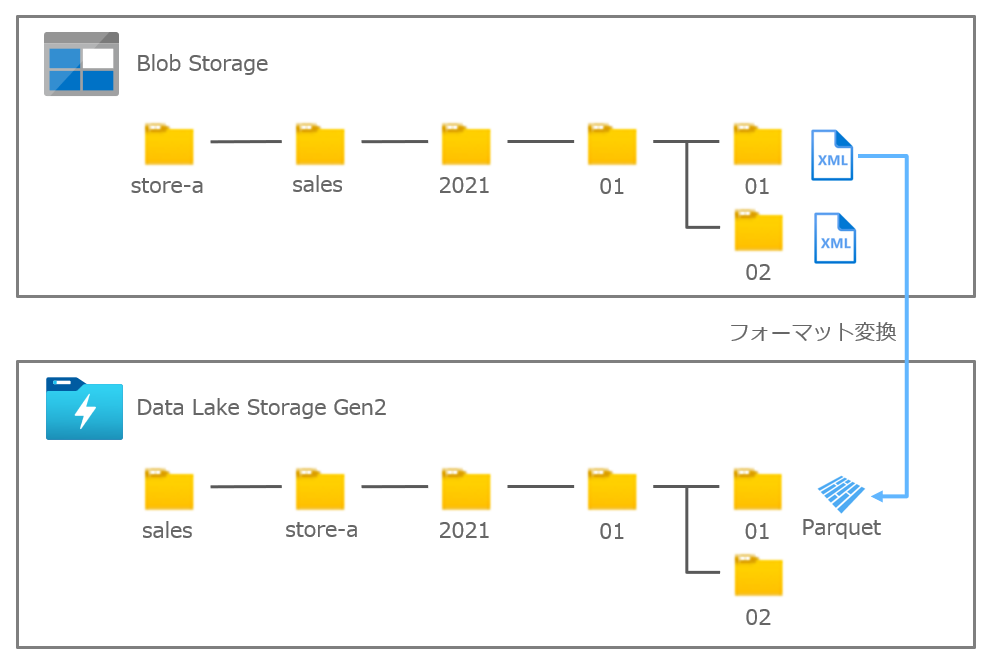
XML ファイルをアップロードする店舗ごとに認証認可(SASトークン)を設定したいので、Blob Storage のコンテナを店舗(store-a)にしています。
一方、ADSL は Datasets でコンテナを固定値にする必要があったので、データ種別(Sales)をコンテナにしています。
Datasets を作成する
利用するリソースごとに、3つの Datasets を作成します。
Dataset for Blob Storage
各店舗から Blob Storage にアップロードされた XML を参照するための Datasets を作成します。
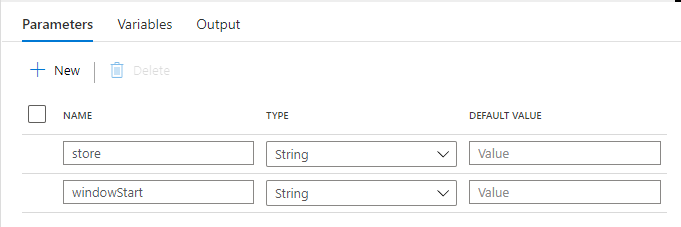
store は、パイプラインを全店舗で共通化して、Trigger を店舗毎に作る想定のため、店舗を受け取ります。
folderPath は、日次でフォルダ分けされた XML の場所を受け取ります。

Linked service には、Blob Storage を指定し、file path でパイプラインから受け取った値を使って動的に読み取りパスを決定します。
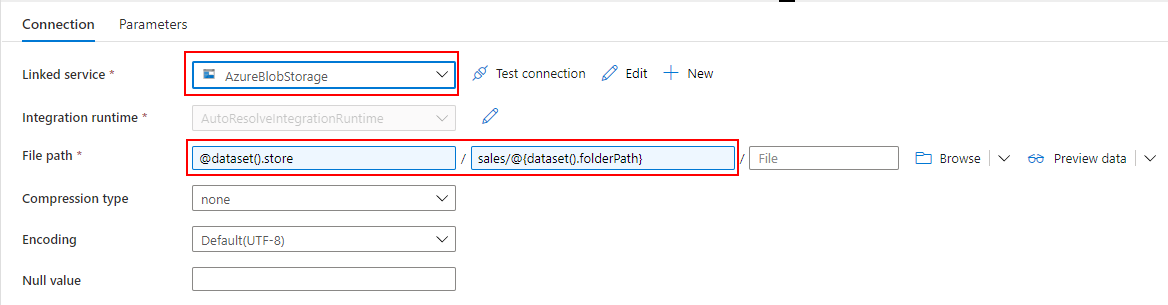
@dataset().store / sales/@{dataset().folderPath}
Dataset for ADLS
ADLS に Parquet をコピーするための Datasets を作成します。
Blob Storage の Datasets と同様に、Parameter を設定します。
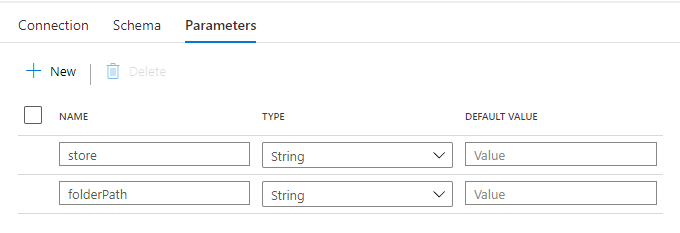
Linked service には、Synapse Analytics の Default Storage(ADLS)を指定し、file path でパイプラインから受け取った値を使って動的にコピー先パスを決定します。

sales / @{dataset().store}/@{dataset().folderPath}
Pipeline を作成する
Copy Data で XML を Parquet に変換するパイプラインの完成イメージです。

Parameter
Datasets と同様に、パイプライン の Parameter を設定します。
Source
Blob Storage に配置されている XML を参照したいので、先ほど作成した Blob Storage 用の Datasets を指定します。
パイプラインの Parameter を Datasets の Parameter に引き渡します。
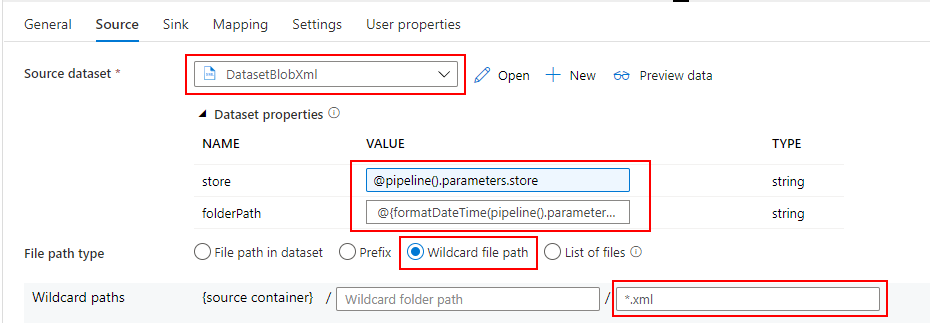
"store": @pipeline().parameters.store, "folderPath": @{formatDateTime(pipeline().parameters.windowStart,'yyyy')}/@{formatDateTime(pipeline().parameters.windowStart,'MM')}/@{formatDateTime(pipeline().parameters.windowStart,'dd')}
file path type では Wildcard file path を選択し、*.xml を指定します。
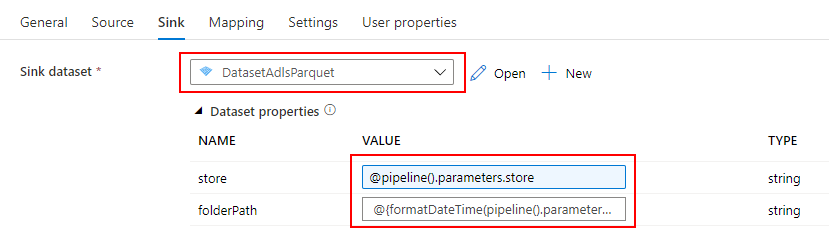
Sink
ADLS に Parquet に変換したファイルをコピーしたいので、先ほど作成した ADLS 用の Datasets を指定します。
Blob Storage の Datasets と同様に、パイプライン の Parameter を引き渡します。
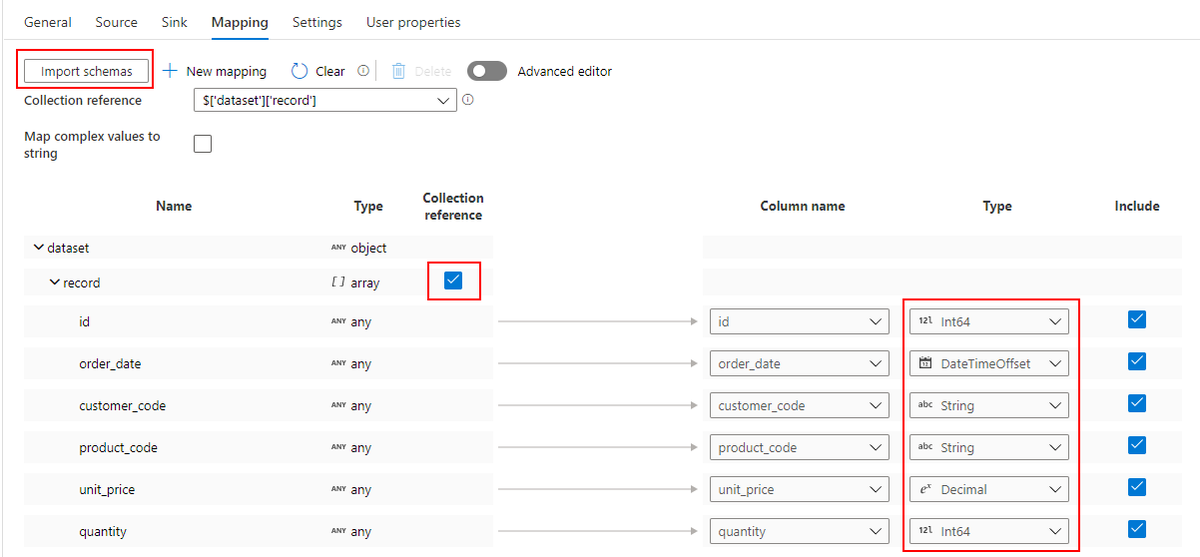
Mapping
import schema ボタンを押すと、XML からスキーマが読み込まれるので、Parquet に変換する際のデータ型を指定します。
XML スキーマが単一レコードの場合はこれだけで OK ですが、今回は1つの XML ファイルに複数レコードがあるので、Collection reference にもチェックを入れます。
Validation
Validation Activity を使って、Blob Storage の XML ファイルの存在をチェックします。
フォルダだけでなく、ファイルの存在もチェックしたいので、Child Items には TRUE を指定します。それ以外の Datasets と Parameter は、同様に設定します。

パイプラインを動作確認する
パイプラインの Trigger now から、Parameter を指定して実行してみます。
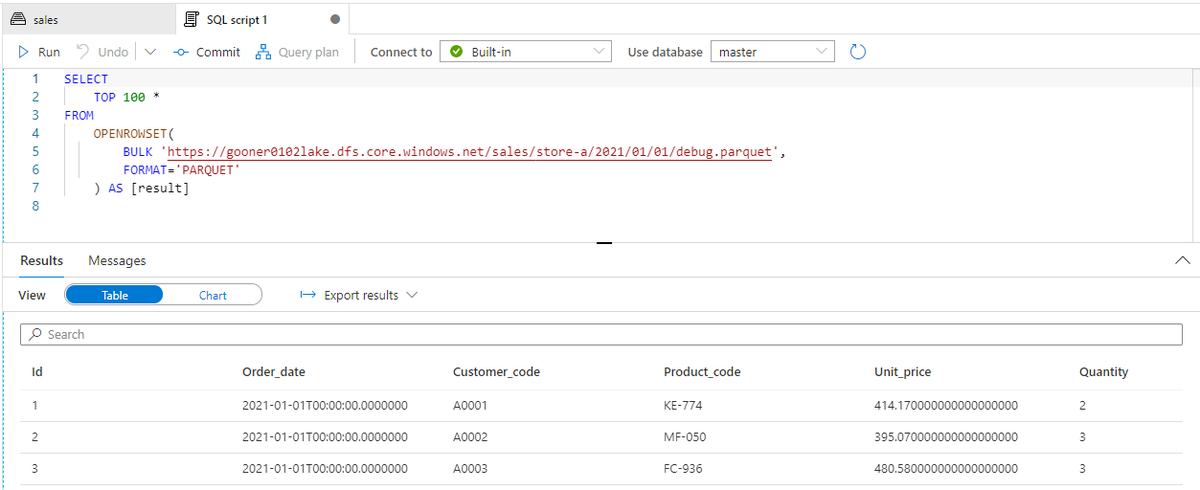
パイプラインが成功すると、XML を Parquet に変換した売上データが ADLS にコピーされたことを確認できます。
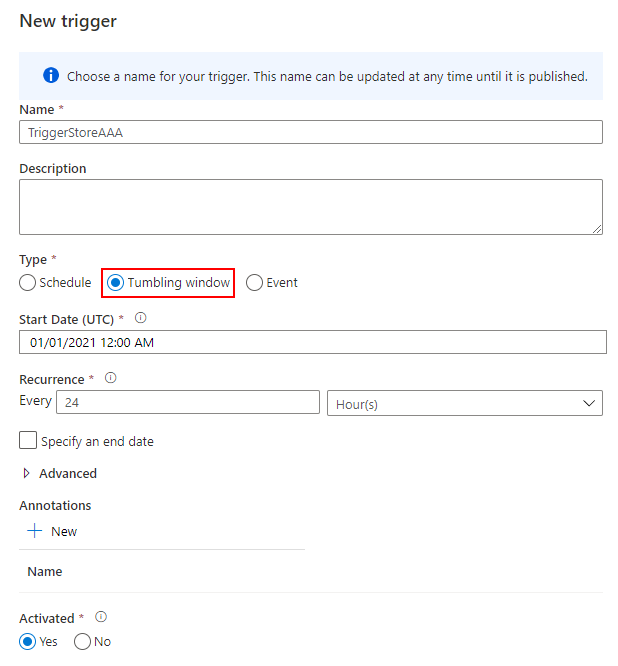
Trigger を作成する
最後に、日次実行するトリガーを作成して完了です。Tumbling window を 24 時間の間隔で実行します。
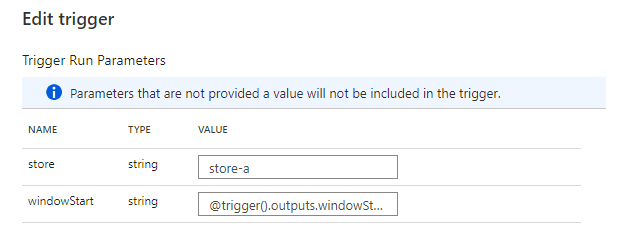
トリガーの実行開始時刻を windowStart でパイプラインに引き渡します。トリガーを店舗ごとに作る想定なので、store を決め打ちしています。
Schedule でも代用できますが、リトライポリシーを設定できる Tumbling window を選択しました。
docs.microsoft.com
まとめ
Azure Synapse Analytics を使って、売上分析プラットフォームの Ingest Layer を作ってみました。
Copy Data が XML に対応したので、解析するパーサーを作りこまなくても、ある程度の解析は可能です。
コピー元ファイルの存在チェックに Validation Activity を使いましたが、パイプライン自体はエラー終了と判断されます。正常終了として扱いたいケースもあるので、そのあたりはもう少し工夫が必要かと思います。
今回のソースコードは、こちらで公開しています。
github.com
Appendix
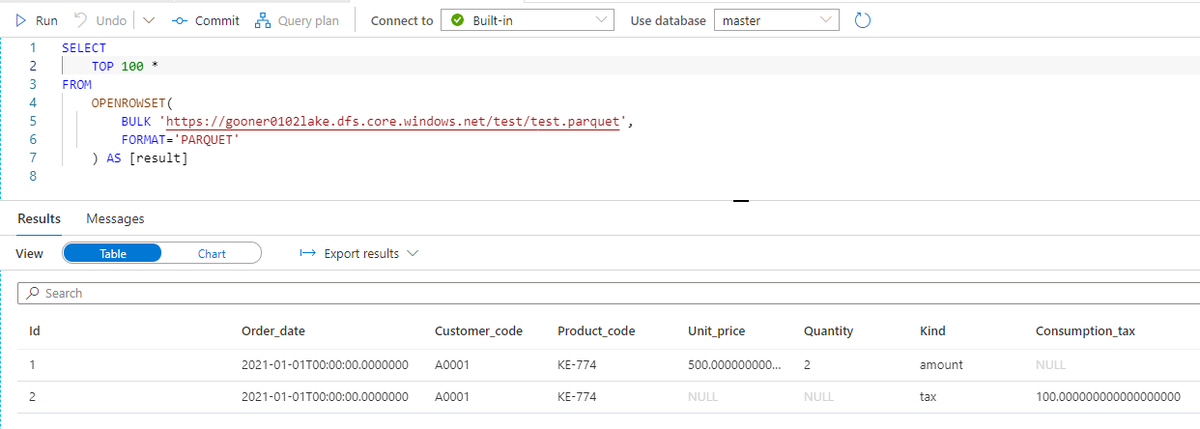
XML スキーマがもう少し複雑になり、record 要素に kind 属性が追加され、売上データの本体価格(amount)と消費税(tax)を分けるケースを見てみましょう。
<?xml version='1.0' encoding='UTF-8'?> <dataset> <record kind = "amount"> <id>1</id> <order_date>2021-01-01T00:00:00Z</order_date> <customer_code>A0001</customer_code> <product_code>KE-774</product_code> <unit_price>500.00</unit_price> <quantity>2</quantity> </record> <record kind = "tax"> <id>2</id> <order_date>2021-01-01T00:00:00Z</order_date> <customer_code>A0001</customer_code> <product_code>KE-774</product_code> <consumption_tax>100.00</consumption_tax> </record> </dataset>
このケースでは、Advanced editor に切り替えての対応が必要となります。
kind 属性は @kind という書式で読み込まれます。さらに、消費税の場合には consumption_tax 要素が必要なので、手動で追加します。
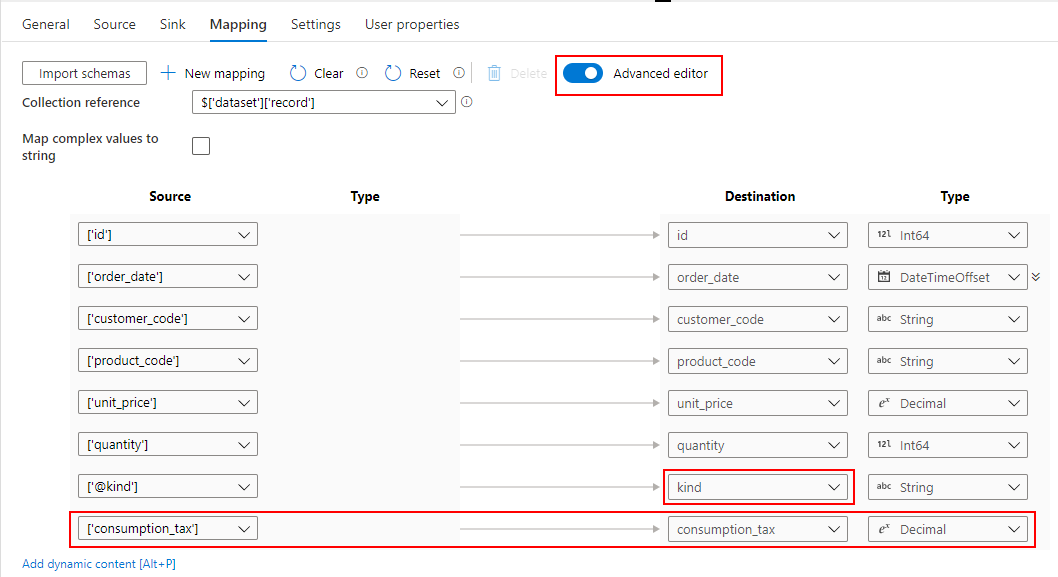
このようにスキーマを定義すると、kind 属性ごとのレコードが Parquet に変換されたことを確認できます。