Azure Synapse Link for Azure Cosmos DB は、Cosmos DB の Container(Transactional Store)とは完全に分離された分析用 Container(Analytical Store)を作ることで、Synapse Analytics から分析処理をできるようにするための機能です。
公式サイトに記載されているレベルの簡単な内容ですが、実際に試してみました。
Azure Synapse Link for Azure Cosmos DB とは
Analytical Store は、複雑な分析クエリに適した列指向の分析ストアで、Transactional Store に対する追加・修正・削除が、ほぼリアルタイムに自動同期されます。
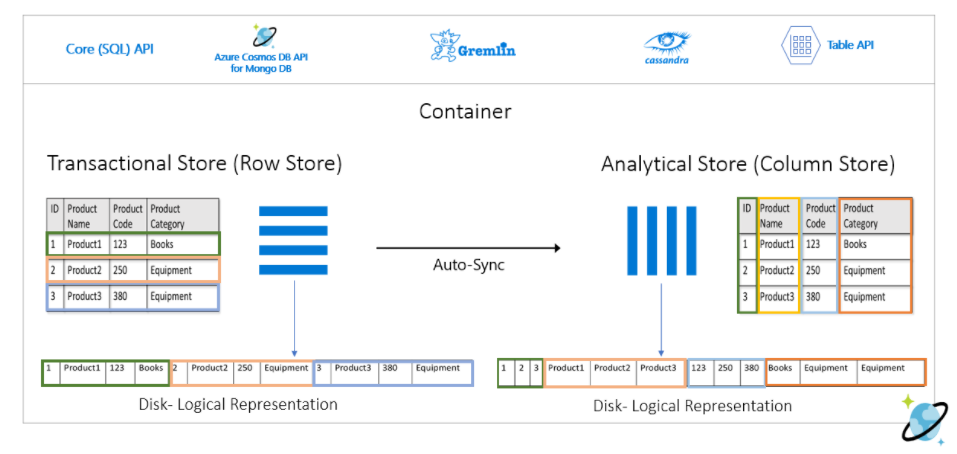
Synapse Analytics では、Transactional Store のワークロードに影響を与えることなく、Serverless SQL Pool もしくは Apache Spark Pool の分析エンジンを選択して Analytical Store に分析クエリを実行できます。
Synapse Link を構成する
Cosmos DB で Synapse Link の機能を有効にすると、Container を作成する際に Analytical Store の指定ができるようになります。

Person という名前の Container を作成し、Mockaroo で作った 1000 件の JSON をアップロードしました。
[{"id":"4bd10e59-3515-4755-ad90-368d63622b1f","first_name":"Claresta","last_name":"Speeding","email":"cspeeding0@goo.gl","gender":"Male"}, {"id":"10b362a3-1924-4a33-871e-8025b021dacd","first_name":"Harald","last_name":"Studman","email":"hstudman1@people.com.cn","gender":"Agender"}, ・・・ {"id":"6ed545dc-24c9-405b-8ee3-760353b3e59e","first_name":"Inglis","last_name":"Kneal","email":"iknealrq@tamu.edu","gender":"Genderqueer"}, {"id":"0a24c1ca-5419-4e97-83ea-df22756fe54c","first_name":"Florry","last_name":"Launder","email":"flaunderrr@wordpress.com","gender":"Genderfluid"}]
Synapse Analytics の Synapse Studio で Linked Service を作成すると、Cosmos DB の Container に接続できるようになります。
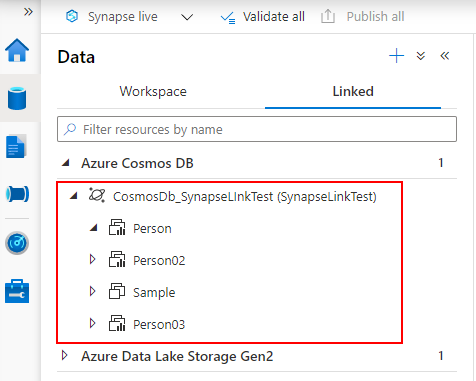
アイコンにグラフが表示されているものが Analytical Store、表示されていないものが Transactional Store となります。
Serverless SQL Pool を使ってクエリを実行する
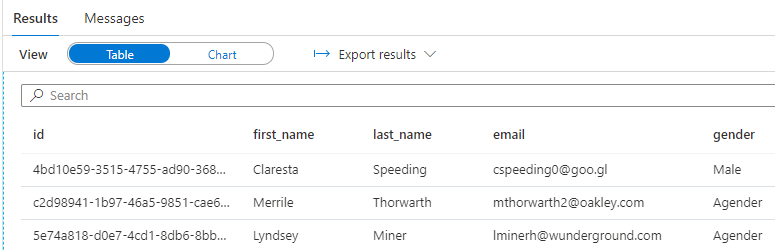
Synapse Studio から、Serverless SQL Pool を使ってクエリを実行してみます。

シンプルなクエリなので分析感はありませんが、Analytical Store からデータを取得できたことを確認できます。
上記のコメントに記載されているように、事前に資格情報(sys.credentials)を登録しておくと、OPENROWSET で SERVER_CREDENTIAL を指定するだけで認証できます。
CREATE CREDENTIAL [gooner0513] WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<Enter your Azure Cosmos DB key here>'
OPENROWSET で Cosmos DB の接続文字列を指定することもできますが、sys.credentials を使ったほうがスマートだと思います。
SELECT TOP 100 * FROM OPENROWSET( 'CosmosDB', 'Account=gooner0513;Database=SynapseLinkTest;Key=<Enter your Azure Cosmos DB key here>', Person) as documents
スキーマを明示的に指定する
OPENROWSET では自動スキーマ推論が働きますが、rid や etag などの Cosmos DB 特有の列は不要なので、WITH 句でスキーマを明示的に指定することができます。
SELECT TOP 100 * FROM OPENROWSET(PROVIDER = 'CosmosDB', CONNECTION = 'Account=gooner0513;Database=SynapseLinkTest', OBJECT = 'Person', SERVER_CREDENTIAL = 'gooner0513' ) WITH ( id varchar(36), first_name varchar(100), last_name varchar(100), email varchar(100), gender varchar(20) ) AS [Person]
View を作成する
このクエリを Analytical Store からデータを取得するたびに記述するのは手間なので、View を作成することもできます。
CREATE DATABASE mydb COLLATE LATIN1_GENERAL_100_CI_AS_SC_UTF8 CREATE OR ALTER VIEW PersonView AS SELECT * FROM OPENROWSET(<200b>PROVIDER = 'CosmosDB', CONNECTION = 'Account=gooner0513;Database=SynapseLinkTest', OBJECT = 'Person', SERVER_CREDENTIAL = 'gooner0513' ) WITH (id varchar(36), first_name varchar(100), last_name varchar(100), email varchar(100), gender varchar(20)) AS [Person]
master データベースには View を作成できないので、mydb というデータベースを作成しました。デフォルトの設定だと日本語が文字化けするので、明示的に照合順序を指定しています。
作成した PersonView にクエリを実行すると、同様の結果を取得することができます。
SELECT TOP 100 * FROM PersonView
入れ子になったオブジェクトを取得する
JSON は、データの中でオブジェクトが入れ子になっているケースがあります。
{ "id": "1", "firstName": "Jack", "lastName": "Dawson", "contactDetails": { "email": "jack@dawson.com", "phone": "+1 555 555-5555" } }
このままクエリを実行すると、contactDetails には JSON が文字列でそのまま返されてしまいます。

そのため、入れ子になっている JSON のプロパティを指定することで、オブジェクトの値を取得できます。
SELECT TOP 100 * FROM OPENROWSET(<200b>PROVIDER = 'CosmosDB', CONNECTION = 'Account=gooner0513;Database=SynapseLinkTest', OBJECT = 'Person02', SERVER_CREDENTIAL = 'gooner0513' ) WITH ( id varchar(36), firstName varchar(100), lastName varchar(100), email varchar(100) '$.contactDetails.email') AS [Person02]

入れ子になったオブジェクトをフラット化する
さらに、入れ子になったオブジェクトが配列になっていることがあります。
{ "id": "1", "firstName": "Jack", "lastName": "Dawson", "contactDetails": [ { "email": "jack@dawson.com", "phone": "+1 555 555-5555", "extension": 5555 }, { "email": "jack@gmail.com", "phone": "+1 777 777-7777", "extension": 7777 } ] }
このままクエリを実行すると、contactDetails には JSON 配列が文字列で返されます。

そのため、入れ子になった配列に対して OPENJSON 関数を使うことで、フラット化した結果を返すことができます。
SELECT TOP 100 * FROM OPENROWSET(<200b>PROVIDER = 'CosmosDB', CONNECTION = 'Account=gooner0513;Database=SynapseLinkTest', OBJECT = 'Person03', SERVER_CREDENTIAL = 'gooner0513' ) WITH (id varchar(36), firstName varchar(100), lastName varchar(100), contactDetails varchar(max)) AS [Person03] CROSS APPLY OPENJSON ( contactDetails ) WITH ( email varchar(100) ) AS contact

Apache Spark Pool を使ってクエリを実行する
Synapse Studio の Notebook で、Apache Spark Pool を使ってクエリを実行してみます。
Serverless SQL Pool と違い、資格情報を Linked Service から取得しているので、スマートに記述できます。

Analytical Store から DataFrame にデータを取得できたことを確認できます。Cosmos DB 特有の列は不要なので、select 句で列名を指定することができます。
df = spark.read\ .format("cosmos.olap")\ .option("spark.synapse.linkedService", "CosmosDb_SynapseLInkTest")\ .option("spark.cosmos.container", "Person")\ .load()\ .select("id", "first_name", "last_name", "email", "gender") display(df.limit(100))

Analytical Store から取得したデータを Spark テーブルに書き込み、分析向けにクレンジングすることもできます。
%%sql
create table PersonTable using cosmos.olap options (
spark.synapse.linkedService 'CosmosDb_SynapseLInkTest',
spark.cosmos.container 'Person'
)
さらに、DataFrame を Cosmos DB の Transactional Store に書き戻すこともできます。Analytical Store は読み取り専用なので、書き込みできません。
df.write.format("cosmos.oltp")\ .option("spark.synapse.linkedService", "CosmosDb_SynapseLInkTest")\ .option("spark.cosmos.container", "Person04")\ .option("spark.cosmos.write.upsertEnabled", "true")\ .mode('append')\ .save()
まとめ
Azure Synapse Link for Azure Cosmos DB で作った Analytical Store に対して、Serverless SQL Pool と Apache Spark Pool からクエリを実行してみました。
- 列指向ストアが自動同期されるので ETL パイプラインを組む必要がない
- ほぼリアルタイムに自動で同期される
- Cosmos DB 側のトランザクションのワークロードに影響を与えずに分析できる
- RU を気にせずに分析クエリを実行できる
- Change Feed を使わずに CQRS パターンを実現できる
といったあたりがメリットだと感じました。
Transactional Store と Analytical Store には、異なる TTL(Time to Live)を構成できるので、アーカイブのような使い方もできそうです。
既存の Container に Analytical Store を追加できない、Synapse Link を一度有効にしたら無効にできない、といった部分には注意が必要です。
Azure Synapse Link はポテンシャルの高いサービスだと思います。現時点では Comos DB のみ対応していますが、将来的には SQL Database などのデータストアも対応する計画があるので、継続してキャッチアップしていきます。