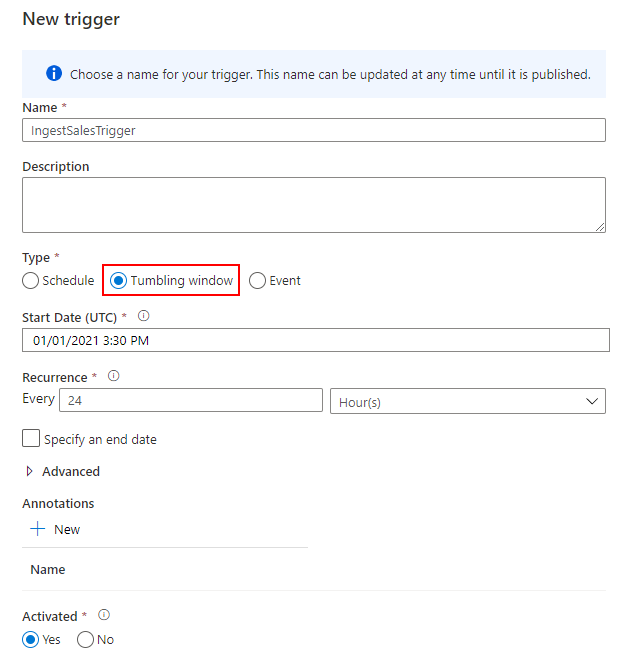
Azure Synapse Analytics は、データのインジェスト→分析→可視化のための開発やモニタリングを統合して管理できるデータ分析プラットフォームです。
先日少し試してみましたが、ポテンシャルの高さを感じる良いサービスです。
gooner.hateblo.jp
今回は、Azure Synapse Analytics を使って売上分析プラットフォームを作ってみます。
売上分析プラットフォームのアーキテクチャ
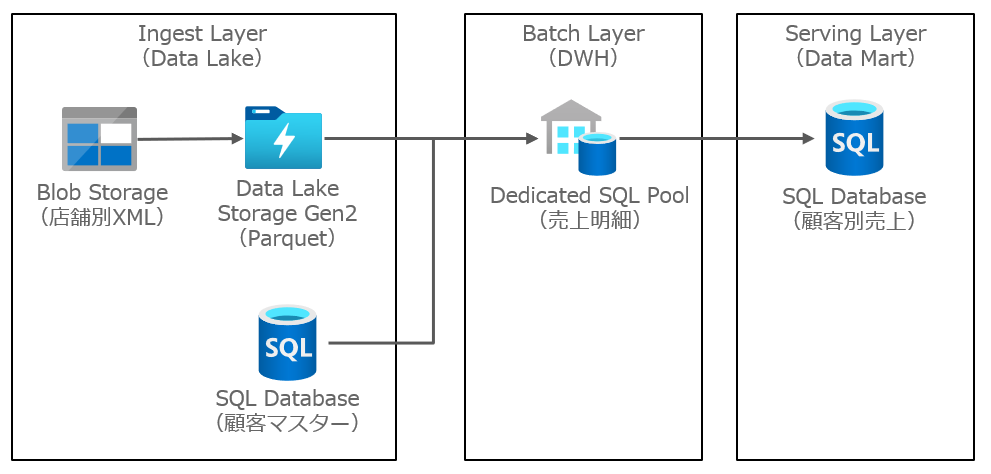
売上分析プラットフォームでは、各店舗の POS システムから売上データを収集し、全店舗のデータをまとめた横断的な売上分析を行う想定シナリオです。
- 各店舗の売上データは、日次単位で XML 形式のファイルがアップロードされる
- 各店舗の顧客マスターは、バラバラのローカルコードが使われているため、標準顧客マスターのコードをマッピングする
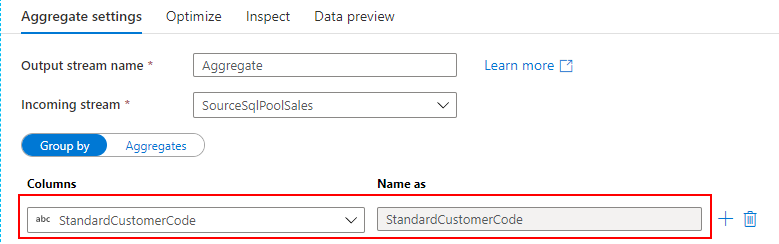
- 全店舗の売上データを集めて、顧客ごとの売上状況を分析する
次のようなアーキテクチャで、売上分析プラットフォームを構築します。
データの準備
売上データ
Blob Storage にアップロードする XML のデータは、mockaroo というサイトを使って、売上データっぽいスキーマを作ります。
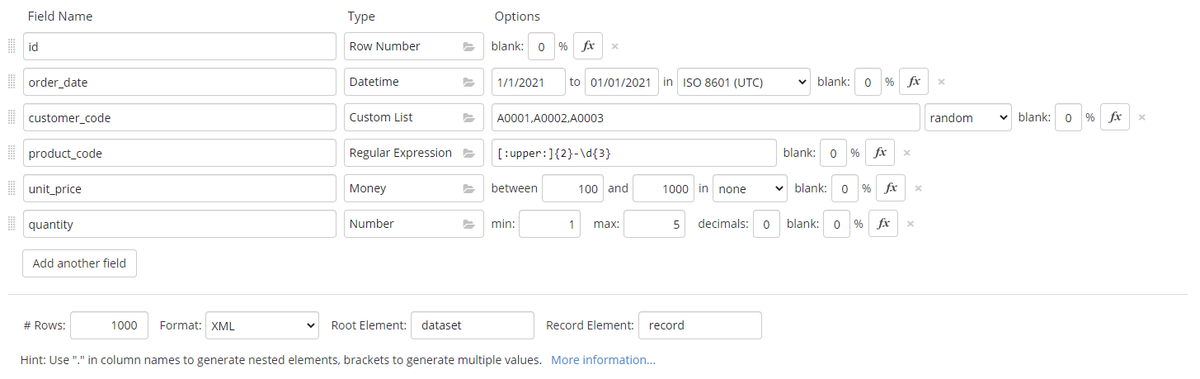
作成した XML は、以下のようなスキーマです。1つの XML ファイルに 1000 件の売上データを作ります。顧客マスターのローカルコード(customer_code)には、A0001/A0002/A0003 という3つのコードをランダムにセットしています。
<?xml version='1.0' encoding='UTF-8'?> <dataset> <record> <id>1</id> <order_date>2021-01-01T00:00:00Z</order_date> <customer_code>A0001</customer_code> <product_code>KE-774</product_code> <unit_price>414.17</unit_price> <quantity>2</quantity> </record> <record> <id>2</id> <order_date>2021-01-01T00:00:00Z</order_date> <customer_code>A0002</customer_code> <product_code>MF-050</product_code> <unit_price>395.07</unit_price> <quantity>3</quantity> </record> </dataset>
顧客マスターのマッピングデータ
SQL Database に、顧客マスターをマッピングするための3つのテーブルを作ります。
- 顧客マスター(Customer)
- 標準顧客マスター(StandardCustomer)
- 顧客マッピング(CustomerMapping)
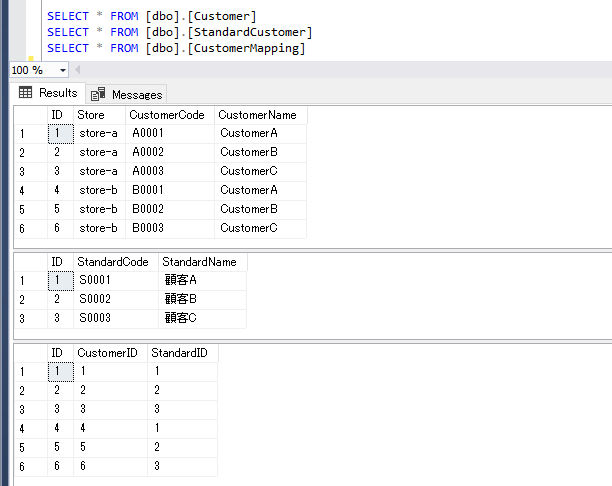
顧客マスターには、店舗を判別する Store 列(e.g. store-a, store-b)を作り、Store + CustomerCode で UNIQUE Key としています。
売上データのローカルコードと突き合わせて、標準コードに変換するための View も作ります。
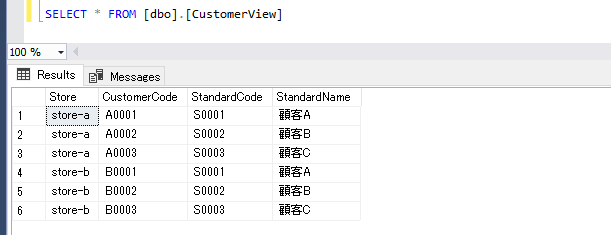
リソースの作成
売上分析プラットフォームで使う Azure リソースを作成し、Azure Synapse Studio で作成する成果物を GitHub で管理できるように設定します。
- Azure Synapse Analytics(ADLS / Dedicated SQL Pool)
- Blob Storage
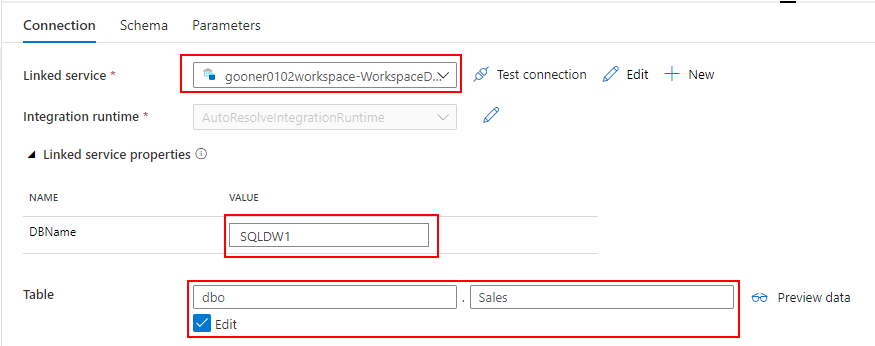
- SQL Database(DbName:Sales)
docs.microsoft.com
Synapse Analytics で管理される ADLS と Dedicated SQL Pool は、デフォルトで Managed Service Identity(MSI)の認証が設定されているので、外部サービスに対しても追加で設定しておきます。
Azure Portal から Access control(IAM) で、Blob Storage に Storage Blob Data Contributor を設定します。MSI の名前は、ワークスペース名で登録されています。
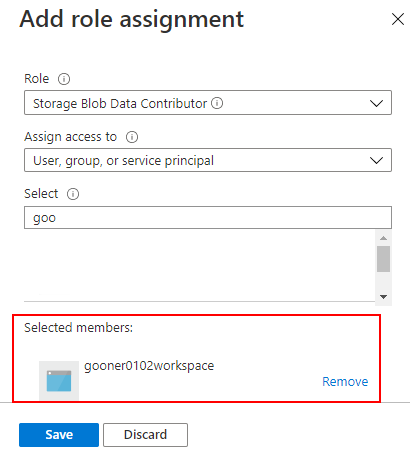
同様に SQL Database にも SQL DB Contributor を設定することに加えて、Active Directory admin で Azure AD の管理者を登録する必要があります。

Ingest Layer
Ingest Layer は、収集したデータから DataLake を作る責務を持ちます。
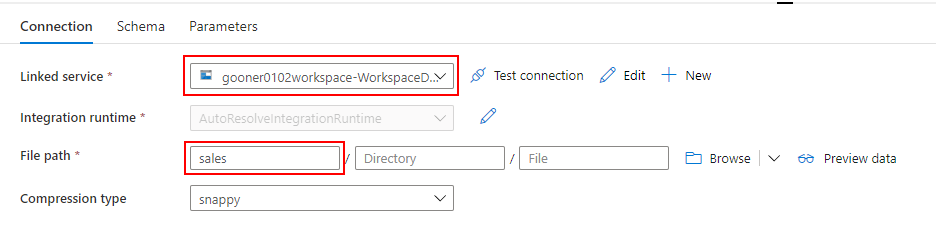
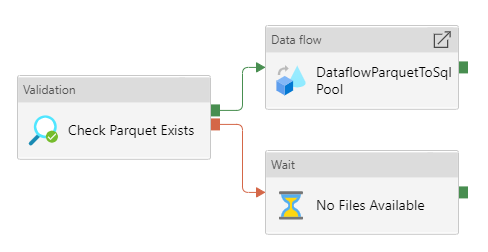
Copy Data を使って、Blob Storage の XML を Parquet に変換して ADLS にコピーするパイプラインを作成します。

詳細は、こちらの記事を参照してください。
gooner.hateblo.jp
gooner.hateblo.jp
Batch Layer
Batch Layer は、DataLake から DWH を作る責務を持ちます。
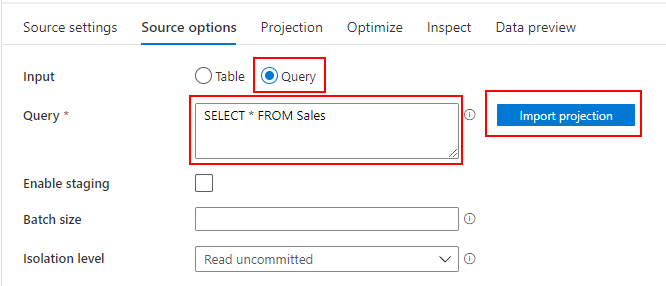
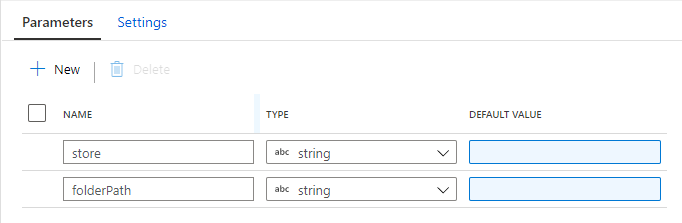
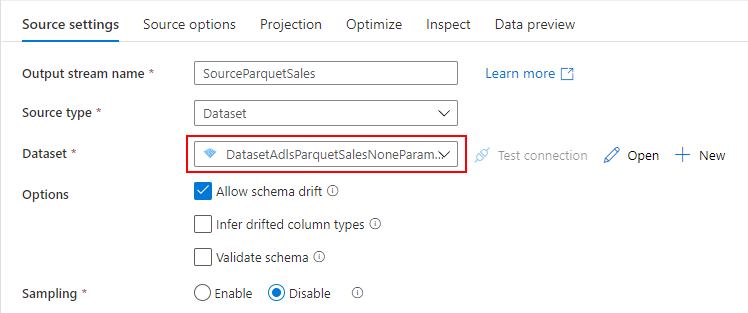
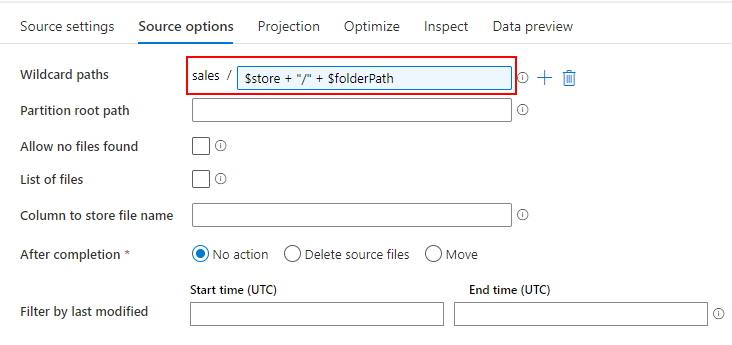
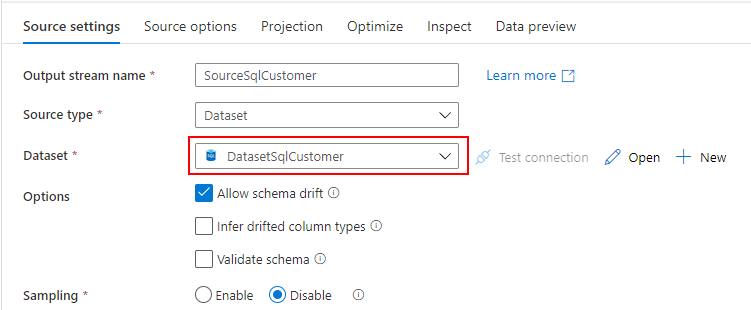
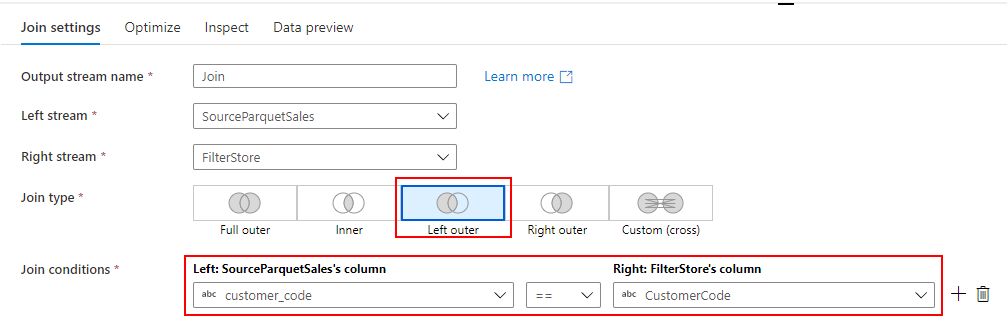
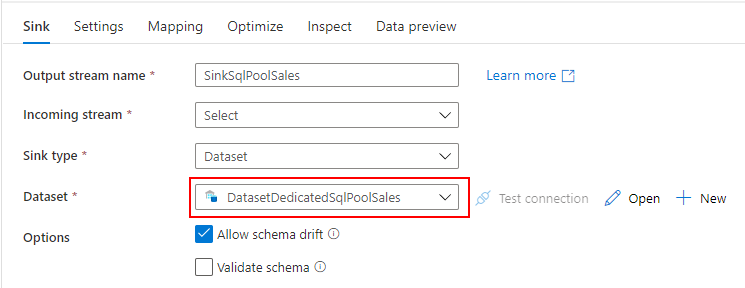
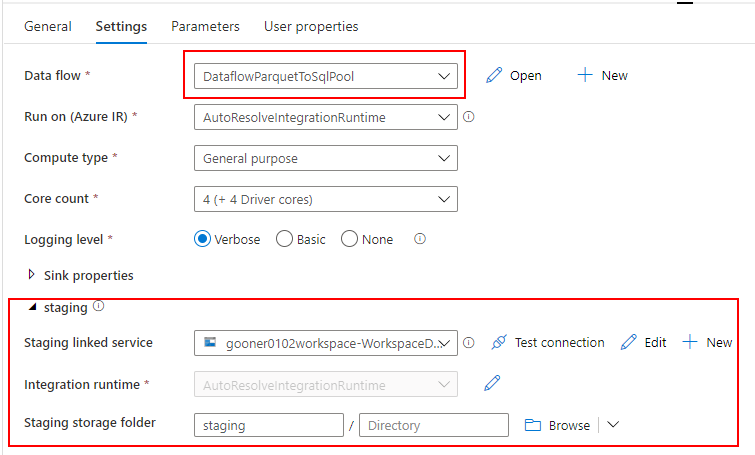
Mapping Data Flow を使って、ADLS の Parquet から Dedicated SQL Pool に売上データを取り込むパイプラインを作成します。
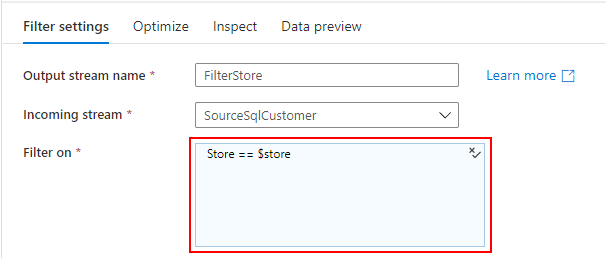
売上データを取り込む過程で、SQL Database の標準顧客マスターと突き合わせて、各店舗のローカルコードを標準コードに変換します。
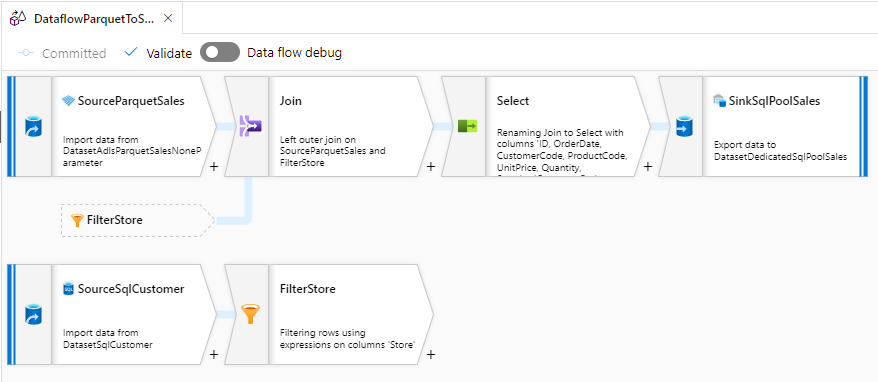
詳細は、こちらの記事を参照してください。
gooner.hateblo.jp
Serving Layer
Serving Layer は、DWH から Data Mart を作る責務を持ちます。
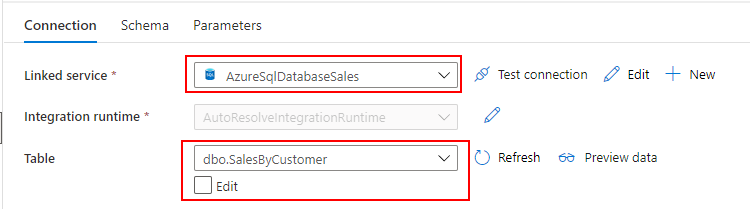
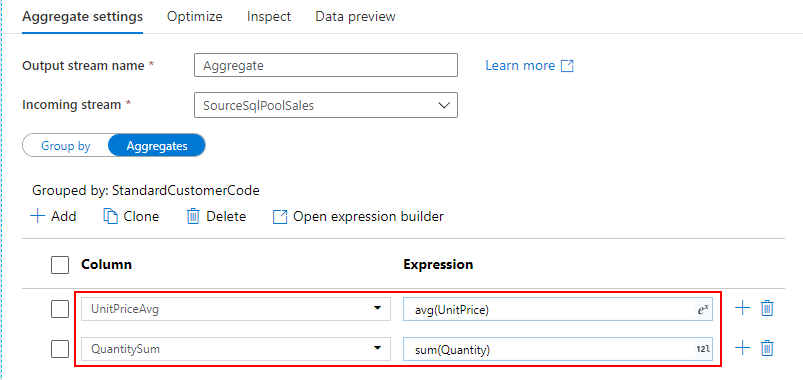
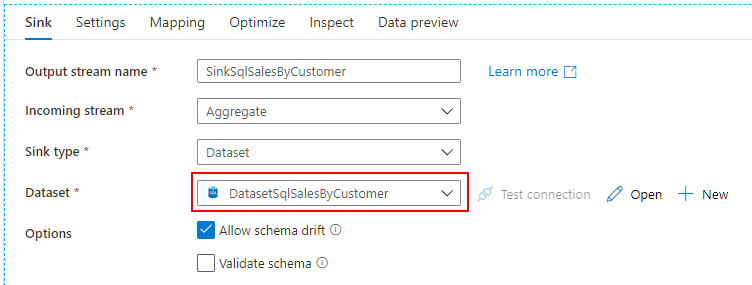
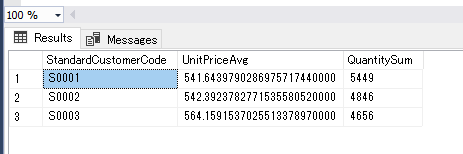
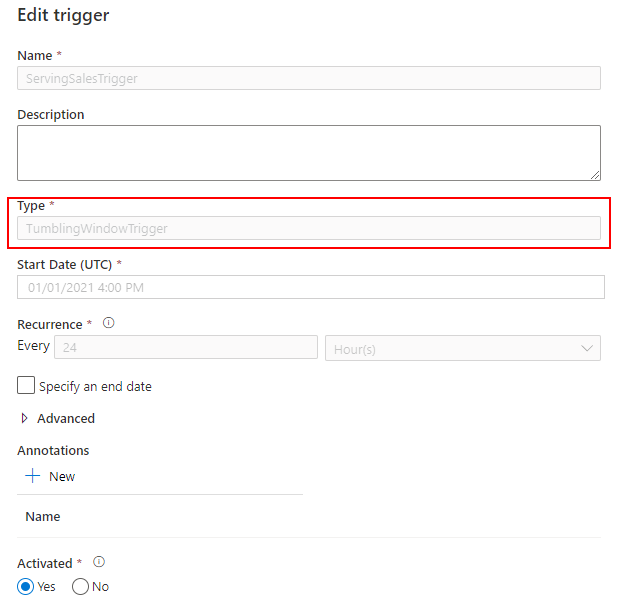
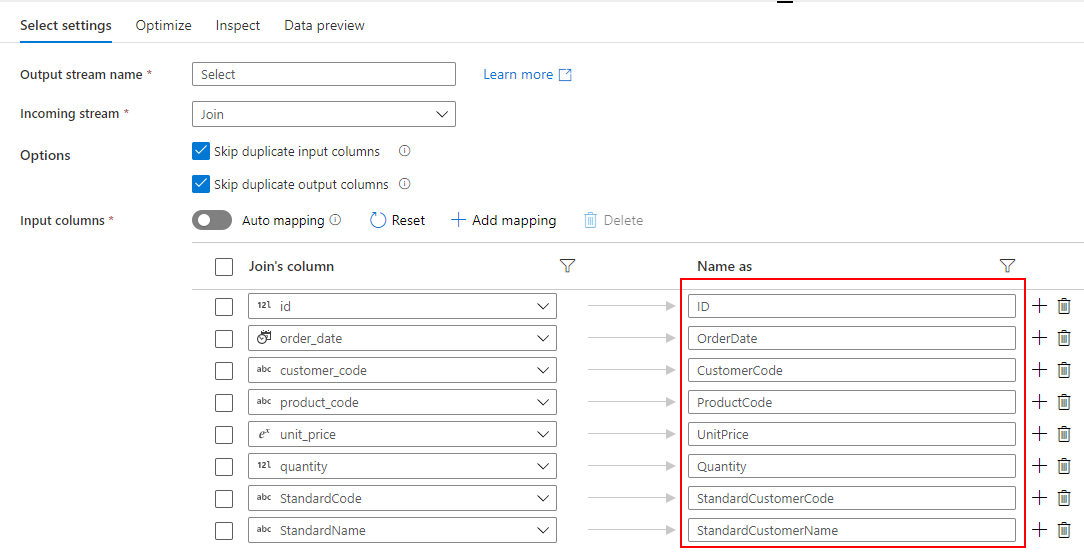
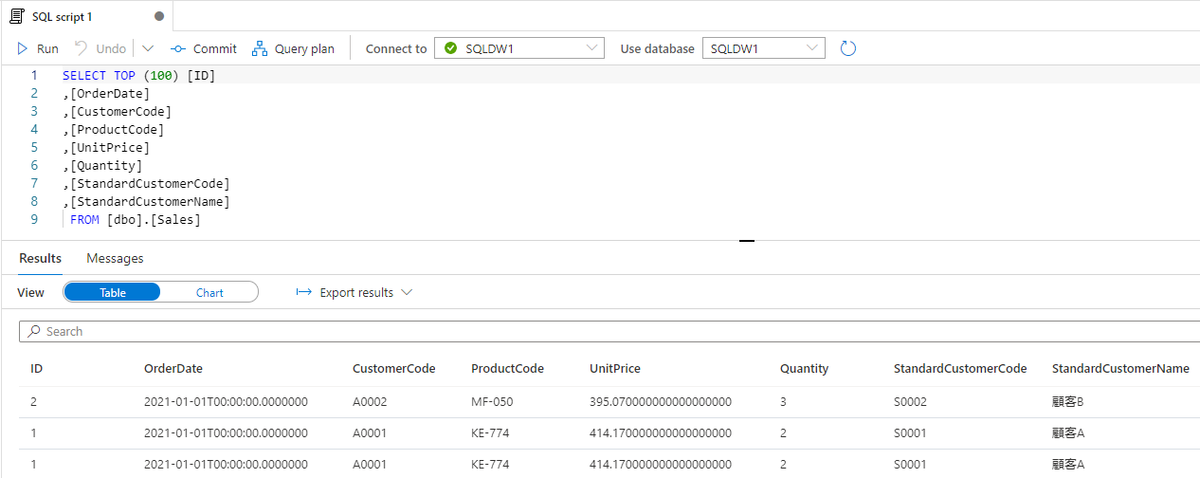
Mapping Data Flow を使って、Dedicated SQL Pool の売上データから SQL Database に顧客別売上データを取り込むパイプラインを作成します。
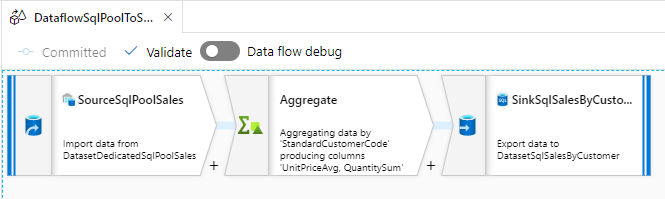
詳細は、こちらの記事を参照してください。
gooner.hateblo.jp
まとめ
Azure Synapse Analytics を使って売上分析プラットフォームを作ってみました。
Spark Pool の Notebook でコードを書いてパイプラインを作るつもりでしたが、Dedicated SQL Pool 向けのコネクタが Append に対応していませんでした。
このレベルのシナリオであれば、Copy Data と Mapping Data Flow で構築できることが分かったので、これはこれでいいのですが、次回は Spark Pool を使ったシナリオを掘り下げていきたいです。
今回のソースコードは、こちらで公開しています。
github.com