Azure Synapse Analytics を使って、売上分析プラットフォームを作ってみました。
ここでは、売上分析プラットフォームの Serving Layer を作る部分を記載します。
想定シナリオや全体アーキテクチャについては、次の記事を参照してください。
gooner.hateblo.jp
Serving Layer

Serving Layer は、DWH から Data Mart を作る責務を持ちます。
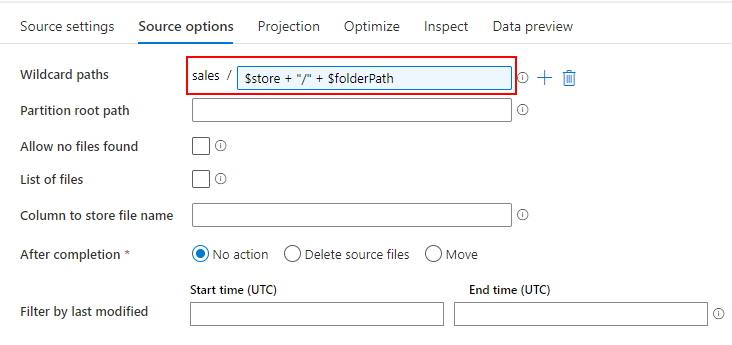
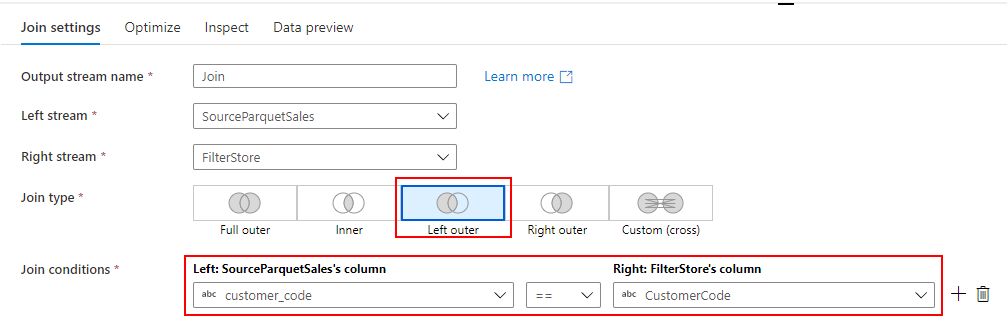
Mapping Data Flow を使って、Dedicated SQL Pool の売上データから SQL Database に顧客別売上データを取り込むパイプラインを作成します。
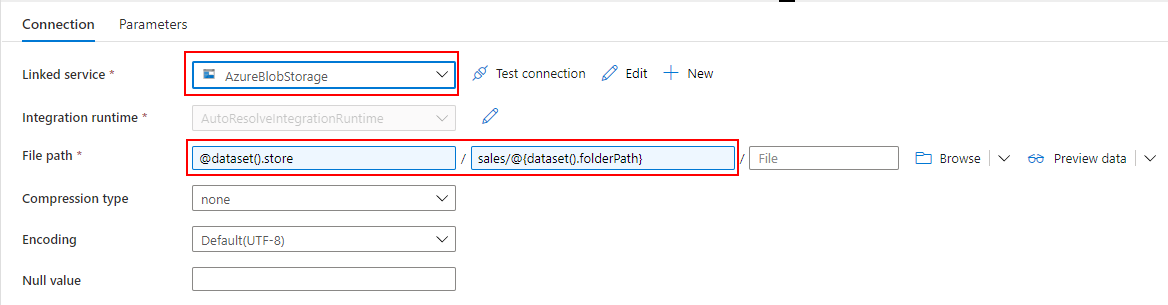
Datasets を作成する
利用するリソースごとに、2つの Datasets を作成します。
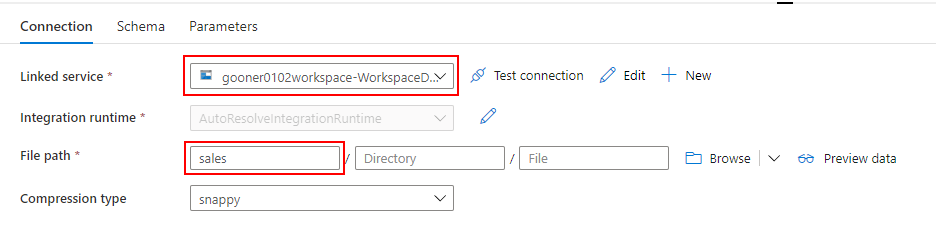
Datasets for Dedicated SQL Pool
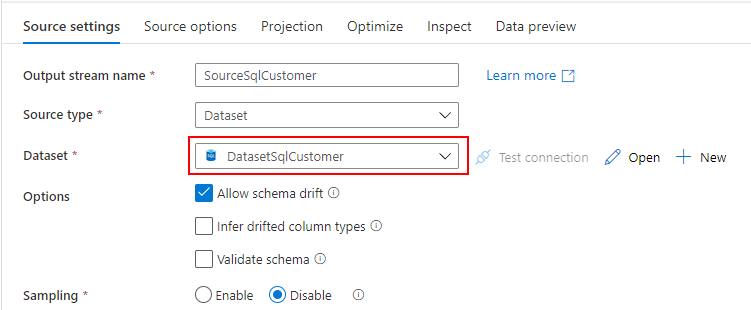
Dedicated SQL Pool から売上データを取り込むための Datasets を作成します。
Linked service には Dedicated SQL Pool を指定し、DbName の SQLDW1 と Table の Sales を入力します。
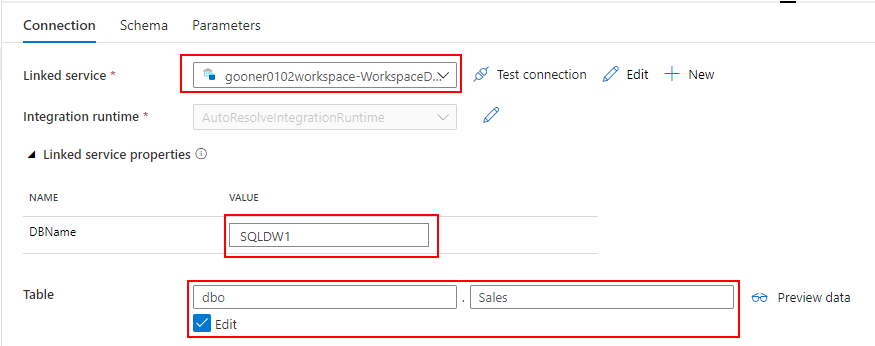
Linked service を指定する際の注意点として、"Azure Synapse Dedicated SQL Pool" ではなく、"Azure Synapse Analytics" を選択してください。Mapping Data Flow から Datasets を指定する際に、なぜか "Azure Synapse Dedicated SQL Pool" を選択できないためです。
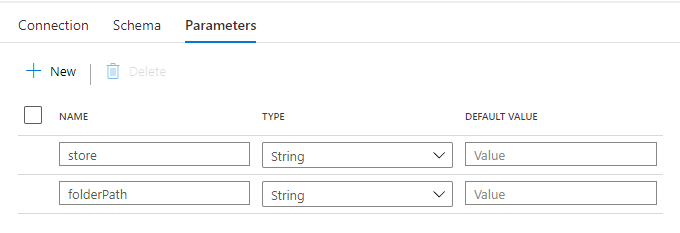
Datasets for SQL Database
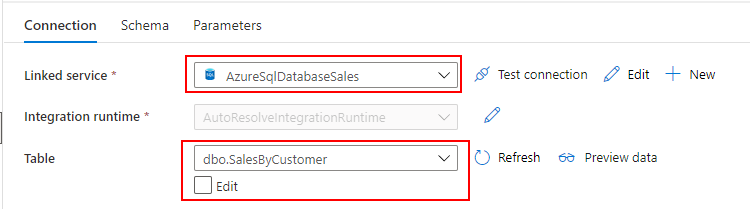
SQL Database の顧客マスターを参照するための Datasets を作成します。
Linked service には SQL Database を指定し、Table で SalesByCustomer を入力します。
Mapping Data Flow を作成する
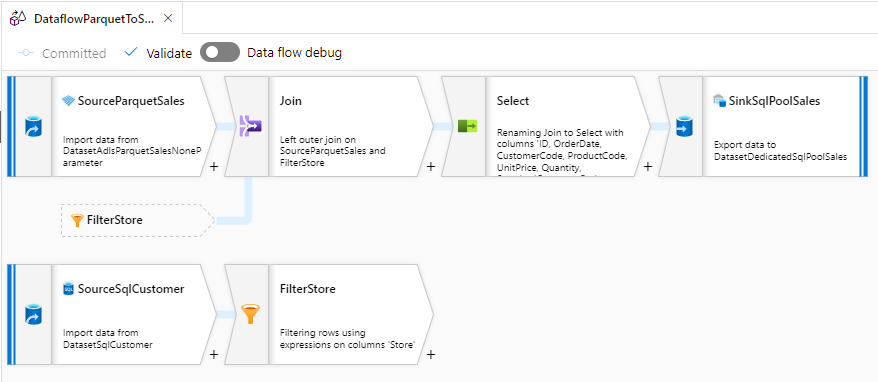
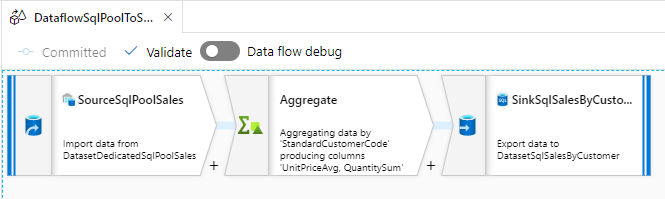
Dedicated SQL Pool の売上データから SQL Database に顧客別売上データを取り込む Mapping Data Flow の完成イメージです。
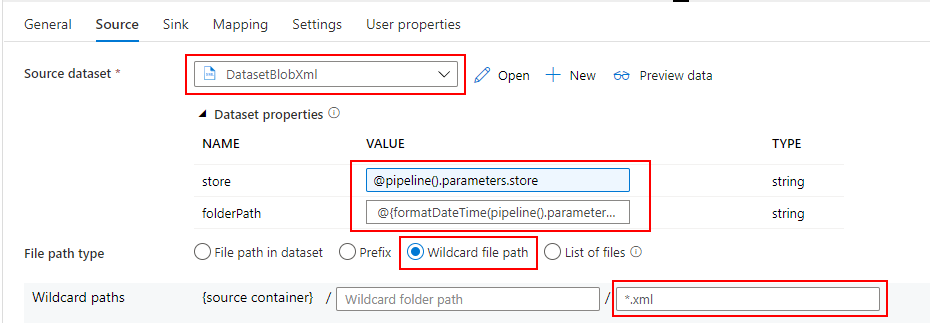
Source
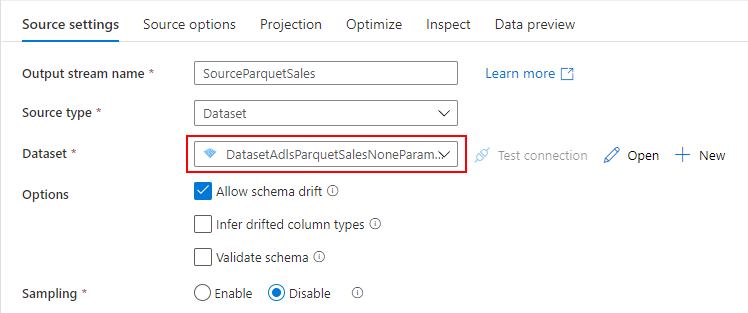
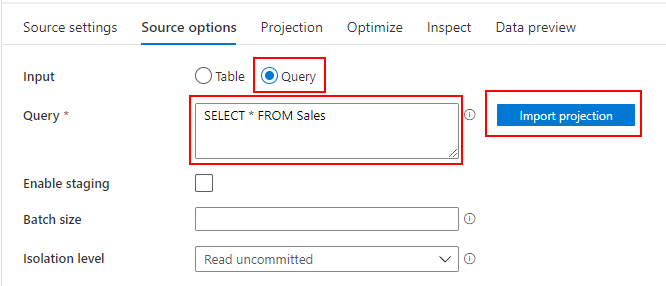
Dedicated SQL Pool から売上データを参照したいので、先ほど作成した Dedicated SQL Pool 用の Datasets を指定します。

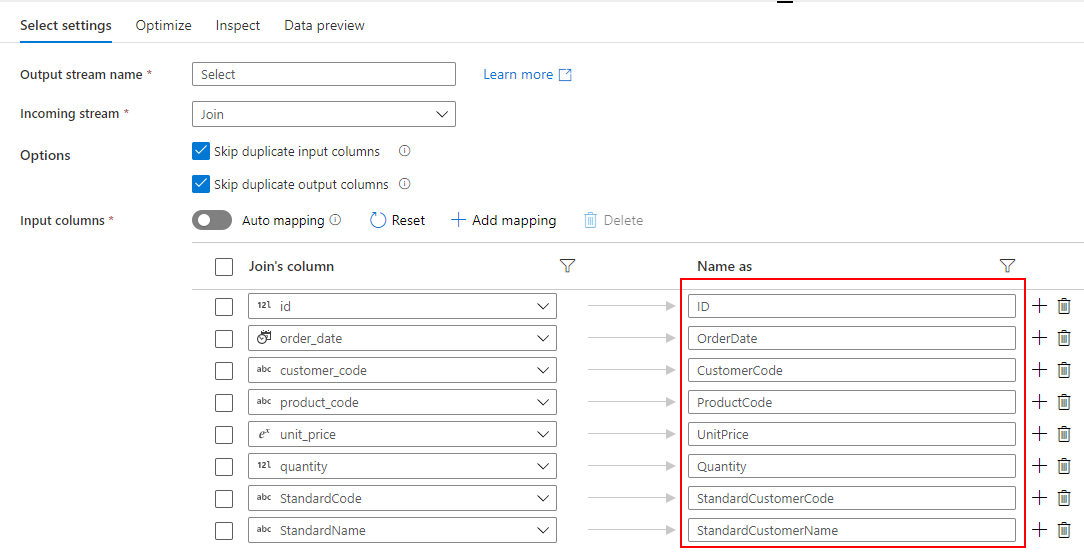
売上データを参照するためのクエリ(SELECT * FROM Sales)を入力し、import projection ボタンをクリックしてスキーマを取り込みます。
Aggregate
顧客別にデータを集計するため、Group By で StandardCustomerCode を指定します。
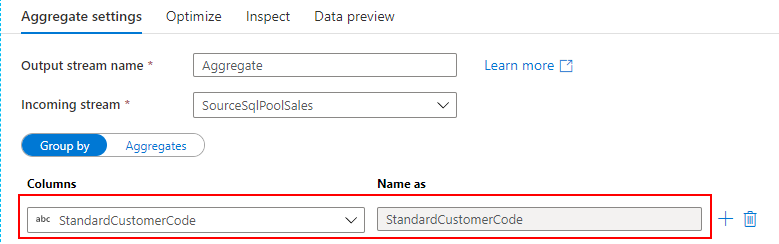
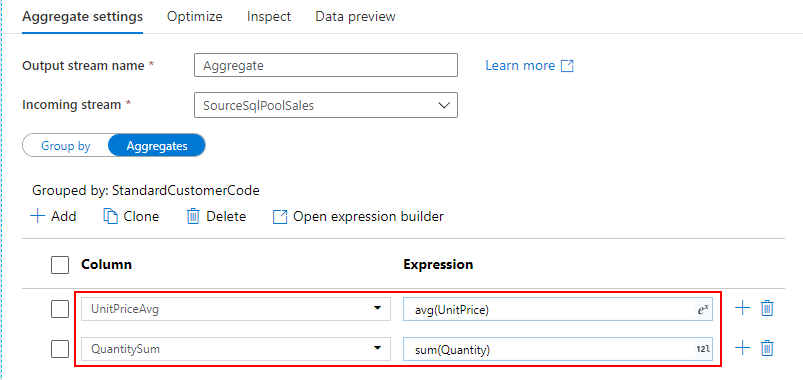
商品単価の平均(UnitPriceAvg)と商品数の合計(QuantitySum)を返すように列を設定します。
Sink
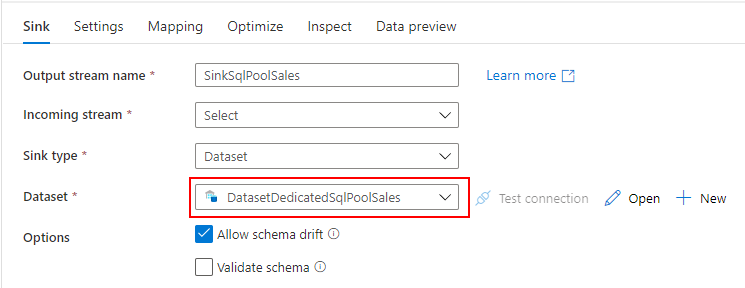
SQL Database に顧客別売上データを取り込み取りたいので、先ほど作成した SQL Database 用の Datasets を指定します。
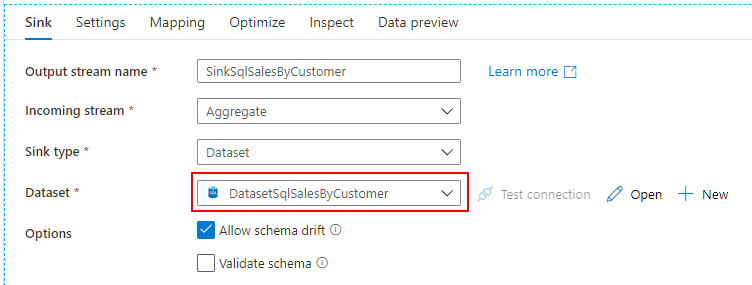
パイプラインが実行される都度、データを作り直したいので、Table action で Truncate Table を選択します。

以上で、Mapping Data Flow の作成が完了しました。
Pipeline を作成する
Mapping Data Flow を実行するパイプラインを作成します。
パイプラインに先ほど作成した Mapping Data Flow を追加するだけで、特別な設定は必要ありません。
パイプラインを動作確認する
パイプラインの Trigger now から実行してみます。
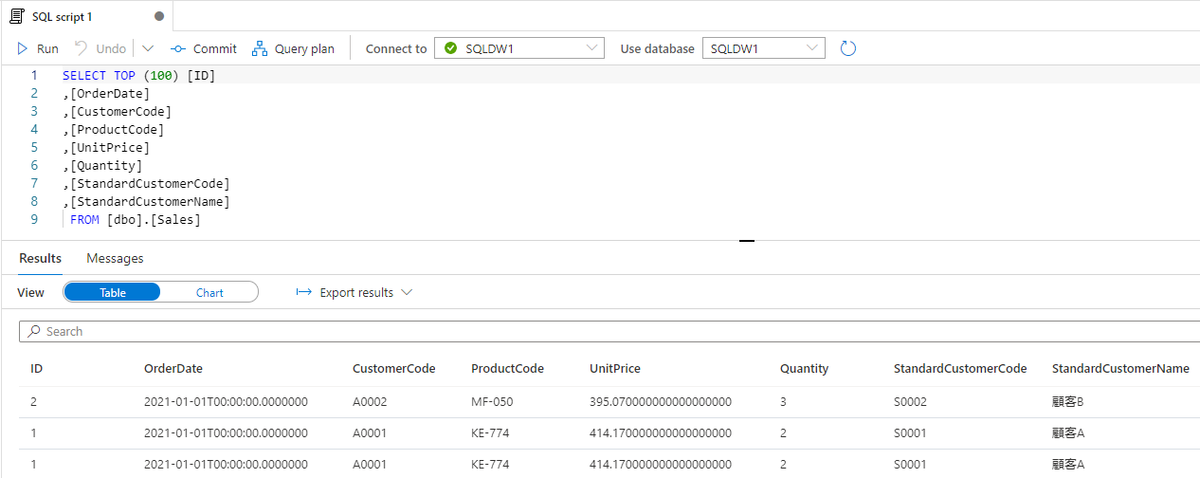
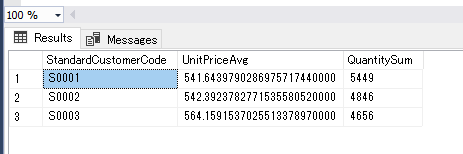
パイプラインが成功すると、顧客別売上データが SQL Database の SalesByCustomer テーブルに取り込まれたことを確認できます。
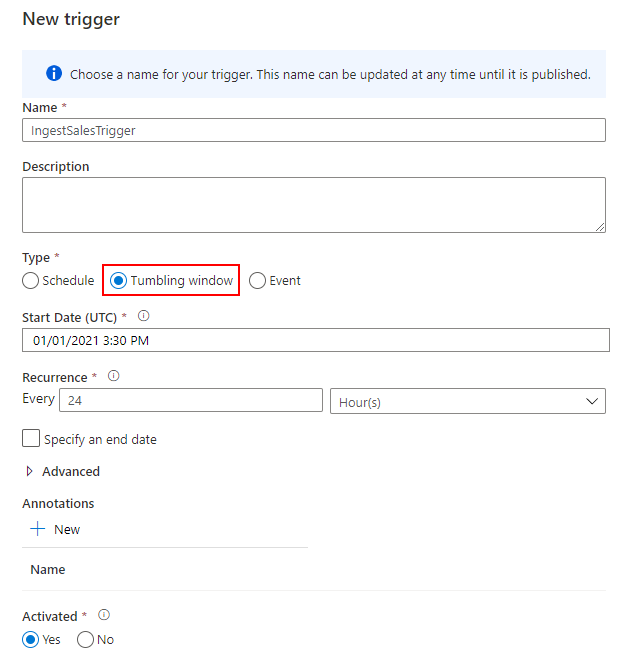
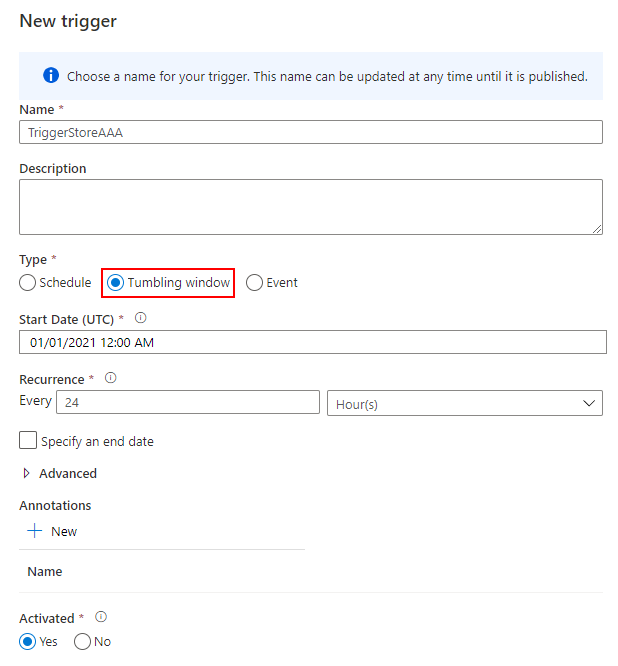
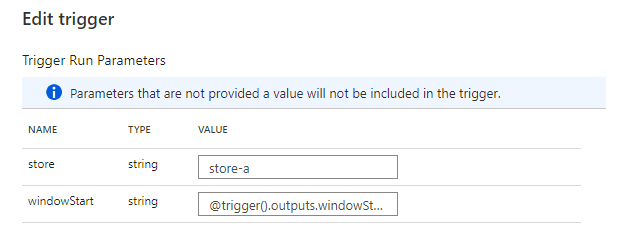
Trigger を作成する
最後に、日次実行するトリガーを作成して完了です。Tumbling window を 24 時間の間隔で実行します。
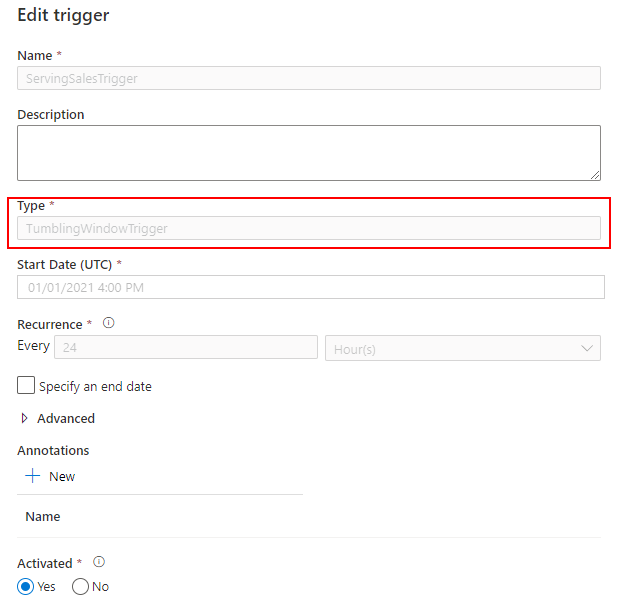
Schedule でも代用できますが、リトライポリシーを設定できる Tumbling window を選択しました。
docs.microsoft.com
まとめ
Azure Synapse Analytics を使って、売上分析プラットフォームの Serving Layer を作ってみました。
Mapping Data Flow のアクティビティを使いこなせるようになって、もう少し複雑なクレンジングも作れるようになりたいところです。
このレイヤーは、Power BI などの分析ツール側に Data Mart を作ってしまう方法もあるので、要件に合わせて選択することになると思います。
今回のソースコードは、こちらで公開しています。
github.com