この記事は、NEXTSCAPE Advent Calendar 2020 の 1 日目 の記事です。
qiita.com
Azure には以前から SQL Data Warehouse(SQL DW)というサービスがありましたが、Synapse Analytics (formerly SQL DW) に名称変更されました。
これとは別に SQL DW が統合された Data Platform のサービスとして、Synapse Analytics (workspaces preview) というサービスが登場しました。
今回は、こちらの Synapse Analytics (workspaces preview) を試してみました。
Synapse Analytics
ひと言でいえば、Azure で Data Platform を作るときに必要となる複数のサービスをまとめて管理できるサービスです。
公式ドキュメントでもいいのですが、Microsoft MVP の方が作ったこちらの資料が分かりやすいです。
従来は、Data Factory / Data Warehouse / Databricks などを組み合わせて、Cold Path と Hot Path の2つのパスを作成するラムダアーキテクチャの構成を組んでいました。
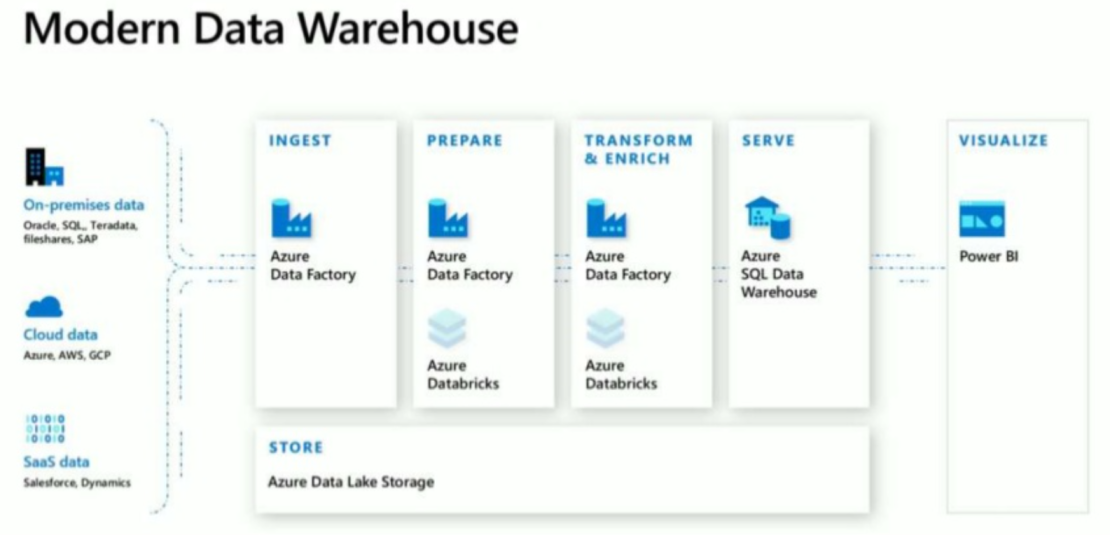
Synapse Analytics では、これらのサービス群が統合された1つのサービスとして提供されています。

統合サービスなので提供される機能の範囲が広いため、まずはデータ分析エンジンの SQL pools と Apache Spark pools を中心にさわっていきたいと思います。
事前準備
Data Platform 系のサービスを試すときに面倒なのが、サンプルデータの作成です。公式ドキュメントでは Microsoft が提供しているオープンデータを使っています。
もう少しお手軽にデータを作りたいときには、mockaroo というサイトがお勧めです。
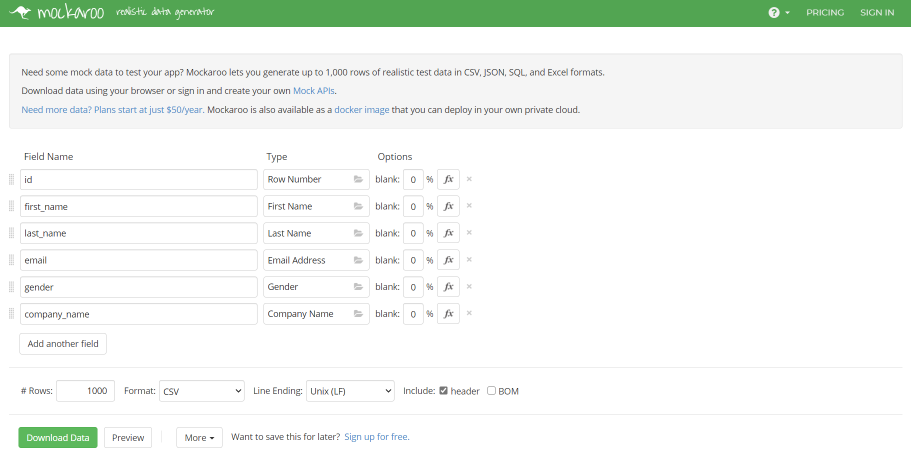
無料でも 1000 件までなら、CSV や JSON のランダムなデータを作成できるので、クエリ検証作業が捗ります。
Synapse Analytics を作成する
Azure Portal で Synapse Analytics (workspaces preview) を作成します。先週ぐらいから、東日本と西日本も使えるようになりました。
Data Lake Storage の BLOB データ共同作成者ロールを自分に割り当てるかどうかのチェックボックスは、忘れずに ON にしておきましょう。その他の項目は、公式ドキュメントを参照してください。
docs.microsoft.com
リソースが作成されると、Azure Portal とは別のツールである Synapse Studio を起動できます。Synapse Analytics を使うメリットの1つで、データのインジェスト→分析→可視化のための開発やモニタリングを行うことができます。
SQL pools
SQL を使った分析エンジンで、Serverless と Dedicated の2つのタイプがあります。どちらのタイプも、SSMS や Azure Data Studio などのツールで接続できます。
Serverless SQL pools
Azure Data Lake Storage(ADLS)においたファイルに対して、SQL を実行できます。対応しているファイルの形式は、CSV / JSON / Parquet の3つです。
mockaroo で作成した CSV ファイルを ADLS の demo コンテナーにアップロードし、Synapse Studio から SQL script でクエリを実行してみます。
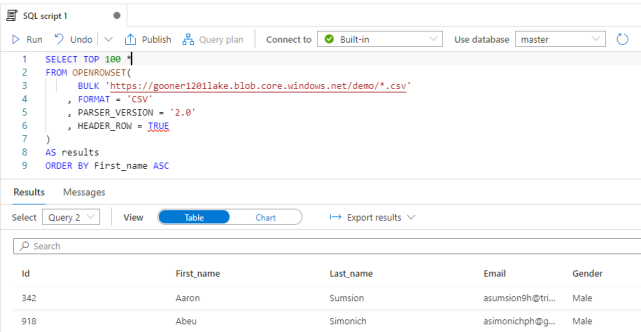
OPENROWSET 関数を使ってデータ ソース (ファイルなど) の内容を読み取って行のセットとして返すことができます。WITH 句を使ってスキーマを指定しなくても、ファイルからスキーマを自動検出してくれます。
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://gooner1201lake.blob.core.windows.net/demo/*.csv' , FORMAT = 'CSV' , PARSER_VERSION = '2.0' , HEADER_ROW = TRUE ) AS results ORDER BY First_name ASC
推論されたデータ型を確認したい場合は、こちらのクエリを実行します。
EXEC sp_describe_first_result_set N' SELECT TOP 100 * FROM OPENROWSET( BULK ''https://gooner1201lake.blob.core.windows.net/demo/*.csv'' , FORMAT = ''CSV'' , PARSER_VERSION = ''2.0'' , HEADER_ROW = TRUE ) AS results ORDER BY First_name ASC';
Serverless SQL pools の master データベースは、照合順序に SQL_Latin1_General_CP1_CI_AS が使われているため、日本語が文字化けします。
そのため、日本語を使える照合順序を指定したデーターベースを作成し、このデーターベースを選択してクエリを実行することで解決できます。
-- データベース作成時に照合順序を指定 CREATE DATABASE mydb COLLATE LATIN1_GENERAL_100_CI_AS_SC_UTF8
Dedicated SQL pools
従来からの SQL DW と同様のサービスなので、ここでは詳しくは説明しません。
Synapse Studio の Manage メニューから、Dedicated SQL pools のデータベースを作成できます。
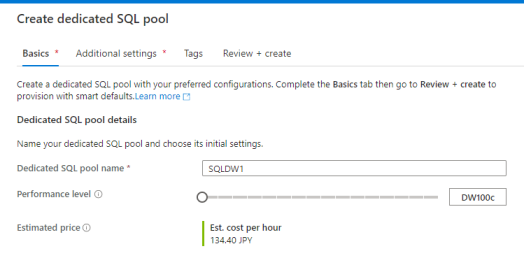
他のサービスに比べて価格が高いので、簡単な検証であれば DW100c を選択しておきましょう。さらに、使わないときはデータベースを停止しておくことで、課金を節約できます。
Apache Spark pools
Spark を使った分析エンジンで、タイプは Serverless のみです。データをメモリに読み込んでキャッシュし、並列にクエリできるのでパフォーマンスに優れています。
Synapse Studio の Manage メニューから、Apache Spark pools を作成できます。
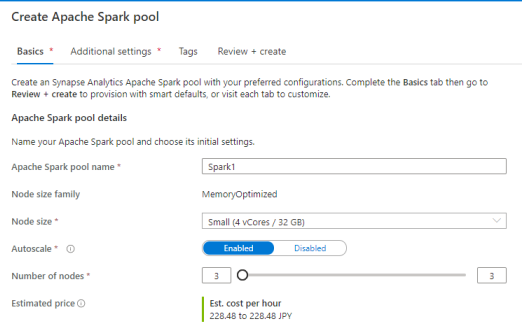
Spark pools には、デフォルトで Spark Core や Anaconda などのコンポーネントが含まれていますが、必要なライブラリを追加構成することもできます。
簡単な検証であれば、Small サイズの Node を最大3つぐらいで十分だと思います。
Synapse Studio から Notebook でコードを実行してみます。PySpark (Python) 以外の言語には、Spark (Scala) / SparkSQL / .NET for Apache Spark (C#) を使うことができます。
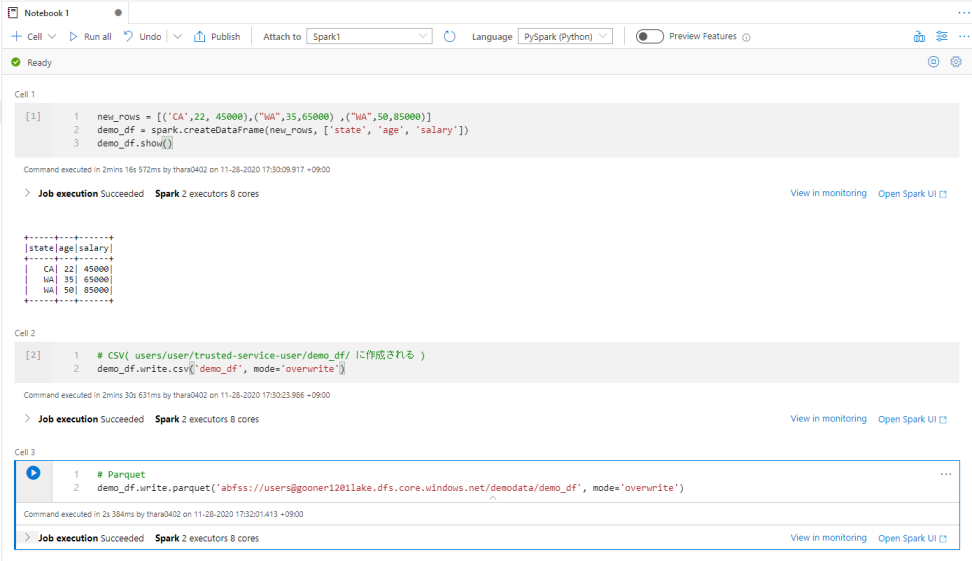
DataFrame を作って CSV と Parquet のファイルにエクスポートしてみます。
# DataFrame の作成 new_rows = [('CA',22, 45000),("WA",35,65000) ,("WA",50,85000)] demo_df = spark.createDataFrame(new_rows, ['state', 'age', 'salary']) demo_df.show() # CSV にエクスポート( users/user/trusted-service-user/demo_df/ に作成される ) demo_df.write.csv('demo_df', mode='overwrite') # Parquet にエクスポート demo_df.write.parquet('abfss://users@gooner1201lake.dfs.core.windows.net/demodata/demo_df', mode='overwrite')
データのインポートとエクスポート
Synapse Studio の Notebook から ADLS / SQL pools / Spark pools に対して、データのインポートとエクスポートを試してみます。
各データストアへの認証には Managed Service Identity(MSI)が使われており、認証周りを意識せずにコードを書けるのは Synapse Analytics を使うメリットの1つだと思います。
ADLS の CSV を Dedicated SQL pools のテーブルにコピーする
ADLS の CSV を DataFrame に読み込みます。
account_name = "gooner1201lake" container_name = "demo" relative_path = "*.csv" adls_path = 'abfss://%s@%s.dfs.core.windows.net/%s' % (container_name, account_name, relative_path) df = spark.read.option('header', 'true').csv(adls_path) df.show(10)
Dedicated SQL pools への転送には scala を使います。異なる言語間で DataFrame を共有できないため、Spark の一時テーブルを経由させます。
df.createOrReplaceTempView("pysparktemptable")
scala への言語の切り替えには、マジックコマンド(%%spark)を使います。Dedicated SQL pools の PolyBase によってデータが転送されます。
%%spark val df2 = spark.sqlContext.sql ("select * from pysparktemptable") df2.write.sqlanalytics("SQLDW1.dbo.Person", Constants.INTERNAL)
Dedicated SQL pools のテーブルを Spark テーブルにコピーする
%%spark val df = spark.read.sqlanalytics("SQLDW1.dbo.Person") df.write.mode("overwrite").saveAsTable("default.t1")
Spark テーブルを Dedicated SQL pools のテーブルにコピーする
Spark テーブルを DataFrame に読み込み、Spark の一時テーブルに転送します。
df = spark.sql("SELECT * FROM default.t1") df.createOrReplaceTempView("pysparktemptable")
Dedicated SQL pools の PolyBase を使って、別テーブルにデータを転送します。
%%spark val df2 = spark.sqlContext.sql ("select * from pysparktemptable") df2.write.sqlanalytics("SQLDW1.dbo.Person2", Constants.INTERNAL)
まとめ
Synapse Analytics について、データ分析エンジンの SQL pools と Apache Spark pools を中心に試してみました。
Synapse Studio を使うことで、データのインジェスト→分析→可視化のための開発やモニタリングを1つで管理でき、各データストアへの認証周りを意識せずにコードを書けるのは便利だと感じました。
次回は、データ分析エンジンの実用的な使い方やパイプライン周りの機能も試していきたいと思います。
gooner.hateblo.jp